SELECT
OBJECT_SCHEMA_NAME(a2.object_id) AS SchemaName,
a2.name AS TableName,
a1.rows as [RowCount],
CAST(ROUND(((a1.reserved + ISNULL(a4.reserved,0)) * 8) / 1024.00, 2) AS NUMERIC(36, 2)) AS ReservedSize_MB,
CAST(ROUND(a1.data * 8 / 1024.00, 2) AS NUMERIC(36, 2)) AS DataSize_MB,
CAST(ROUND((CASE WHEN (a1.used + ISNULL(a4.used,0)) > a1.data THEN (a1.used + ISNULL(a4.used,0)) - a1.data ELSE 0 END) * 8 / 1024.00, 2) AS NUMERIC(36, 2)) AS IndexSize_MB,
CAST(ROUND((CASE WHEN (a1.reserved + ISNULL(a4.reserved,0)) > a1.used THEN (a1.reserved + ISNULL(a4.reserved,0)) - a1.used ELSE 0 END) * 8 / 1024.00, 2) AS NUMERIC(36, 2)) AS UnusedSize_MB
FROM
(SELECT
ps.object_id,
SUM (CASE WHEN (ps.index_id < 2) THEN row_count ELSE 0 END) AS [rows],
SUM (ps.reserved_page_count) AS reserved,
SUM (CASE
WHEN (ps.index_id < 2) THEN (ps.in_row_data_page_count + ps.lob_used_page_count + ps.row_overflow_used_page_count)
ELSE (ps.lob_used_page_count + ps.row_overflow_used_page_count)
END
) AS data,
SUM (ps.used_page_count) AS used
FROM sys.dm_db_partition_stats ps
GROUP BY ps.object_id) AS a1
LEFT OUTER JOIN
(SELECT
it.parent_id,
SUM(ps.reserved_page_count) AS reserved,
SUM(ps.used_page_count) AS used
FROM sys.dm_db_partition_stats ps
INNER JOIN sys.internal_tables it ON (it.object_id = ps.object_id)
WHERE it.internal_type IN (202,204)
GROUP BY it.parent_id) AS a4 ON (a4.parent_id = a1.object_id)
INNER JOIN sys.all_objects a2 ON ( a1.object_id = a2.object_id )
WHERE a2.type <> N'S' and a2.type <> N'IT'
ORDER BY ReservedSize_MB DESC
다음 예제를 복사하여 쿼리 창에 붙여넣고실행을 선택합니다. 이 예에서는모델데이터베이스의 복구 모델을 배우기 위해sys.databases카탈로그 뷰를 쿼리하는 방법을 보여줍니다.
복구 모델을 변경하려면
데이터베이스 엔진에 연결합니다.
표준 도구 모음에서새 쿼리를 선택합니다.
다음 예제를 복사하여 쿼리 창에 붙여넣고실행을 선택합니다. 이 예에서는modelALTER DATABASEFULL문의SET RECOVERY옵션을 사용하여데이터베이스의 복구 모델을로 변경하는 방법을 보여 줍니다.
-- 복구 모델을 보려면
SELECT name, recovery_model_desc
FROM sys.databases
WHERE name = 'model' ;
-- 복구 모델을 변경하려면
USE [master] ;
ALTER DATABASE [model] SET RECOVERY FULL ;
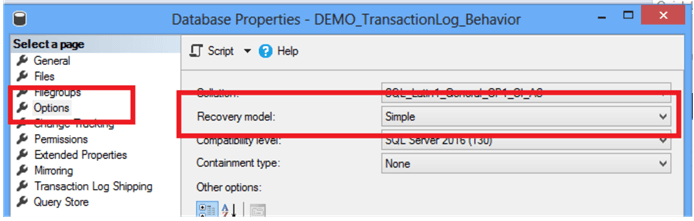
SSMS에서 하기.
DB 속성에서 옵션 들어가서 복구모델 선택하기.
단순(Simple) 데이터베이스 복구 모델을 선택하는 몇 가지 이유는 다음과 같습니다.
개발 및 테스트 데이터베이스에 가장 적합합니다.
데이터 손실이 허용되는 단순한 보고 또는 애플리케이션 데이터베이스
장애 시점 복구는 전체 및 개별 백업 전용입니다.
관리 오버헤드 없음
다음을 지원합니다.
전체 백업
차등 백업
복사 전용 백업
파일 백업
부분 백업
장점: 고성능 대량 복사 작업이 가능하고 로그 공간을 확보하여 공간 요청을 작게 유지합니다.
단점: 가장 최근의 데이터베이스 또는 불일치 백업을 다시 빌드해야 하므로 변경됩니다.
Full
전체 복구 모델을 사용하면 SQL Server는 사용자가 백업할 때까지 트랜잭션 로그를 예약합니다.이 복구 모델에서는 모든 거래(DDL(데이터 정의 언어) + DML(데이터 조작 언어))가 트랜잭션 로그 파일에 완전히 기록됩니다.로그 순서는 손상되지 않고 데이터베이스가 작업을 복원할 수 있도록 보존됩니다.단순 복구 모델과 달리 트랜잭션 로그 파일은 CHECKPOINT 작업 중에 자동으로 잘리지 않습니다.
데이터베이스 오류가 발생했을 때 전체 복구 모델을 사용하여 데이터베이스를 복원하는 가장 유연성을 얻을 수 있습니다. 지정 시간 복원, 페이지 복원 및 파일 복원을 포함한 모든 복원 작업이 지원됩니다.
전체 데이터베이스 복구 모델을 선택하는 이유:
미션 크리티컬 애플리케이션 지원
고가용성 키 설계
0 또는 명목 데이터 손실로 모든 데이터 복구를 용이하게 하기 위해
데이터베이스가 여러 파일 그룹을 갖도록 설계되었으며 읽기/쓰기 보조 파일 그룹 및 선택적으로 읽기 전용 파일 그룹의 부분적 복원을 수행하려는 경우
임의 시점 복원 허용
개별 시트 복원
높은 관리 오버헤드 유지
다음을 지원합니다.
전체 백업
차등 백업
트랜잭션 로그 백업
복사 전용 백업
파일 및/또는 파일 그룹 백업
부분 백업
장점: 데이터 파일의 유실 또는 손상으로 인한 작업 오작동이 없습니다.임의의 시점으로 회복될 수 있습니다.
단점: 로그가 손상되면 가장 최근의 로그 백업 이후의 변경 사항을 다시 작성해야 합니다.
데이터베이스가 개발 또는 테스트 서버인 경우 단순 복구 모델이 대부분 적합해야 합니다.그러나 데이터베이스가 프로덕션 데이터베이스인 경우 일반적으로 전체 복구 모델을 사용하는 것이 좋습니다.전체 복구 모델은 대량 로그 복구 모델로 보완할 수 있습니다.물론 데이터베이스가 작거나 데이터 웨어하우스의 일부이거나 데이터베이스가 읽기 전용인 경우에도 마찬가지입니다.