생성형 AI의 등장 이후 가장 뜨거운 화두는 단연 오픈AI입니다. 하지만 그들은 단순히 강력한 모델을 만드는 데 그치지 않습니다. 오픈AI의 전략은 마치 체스 게임처럼 장기적인 안목으로 설계된 '10년 판짜기'에 가깝죠. 표면적으로는 놀라운 기술적 진보가 전부인 것처럼 보이지만, 그 이면에는 AI 시대의 모든 기술과 시장을 직접 설계하려는 거대한 야망이 숨겨져 있습니다.
오픈AI는 크게 두 가지 핵심 축을 중심으로 기업 개발 전략을 전개하고 있습니다. 첫째는 수직적으로 통합된 기술 스택을 구축하기 위한 전략적 인수이며, 둘째는 지배적인 플랫폼 생태계를 조성하기 위한오픈AI 스타트업 펀드를 통한 벤처 투자입니다. 이러한 이중적 접근 방식은 오픈AI가 연구 중심의 조직에서 성숙한 제품 주도형 기술 대기업으로 빠르게 전환하고 있음을 보여주죠.
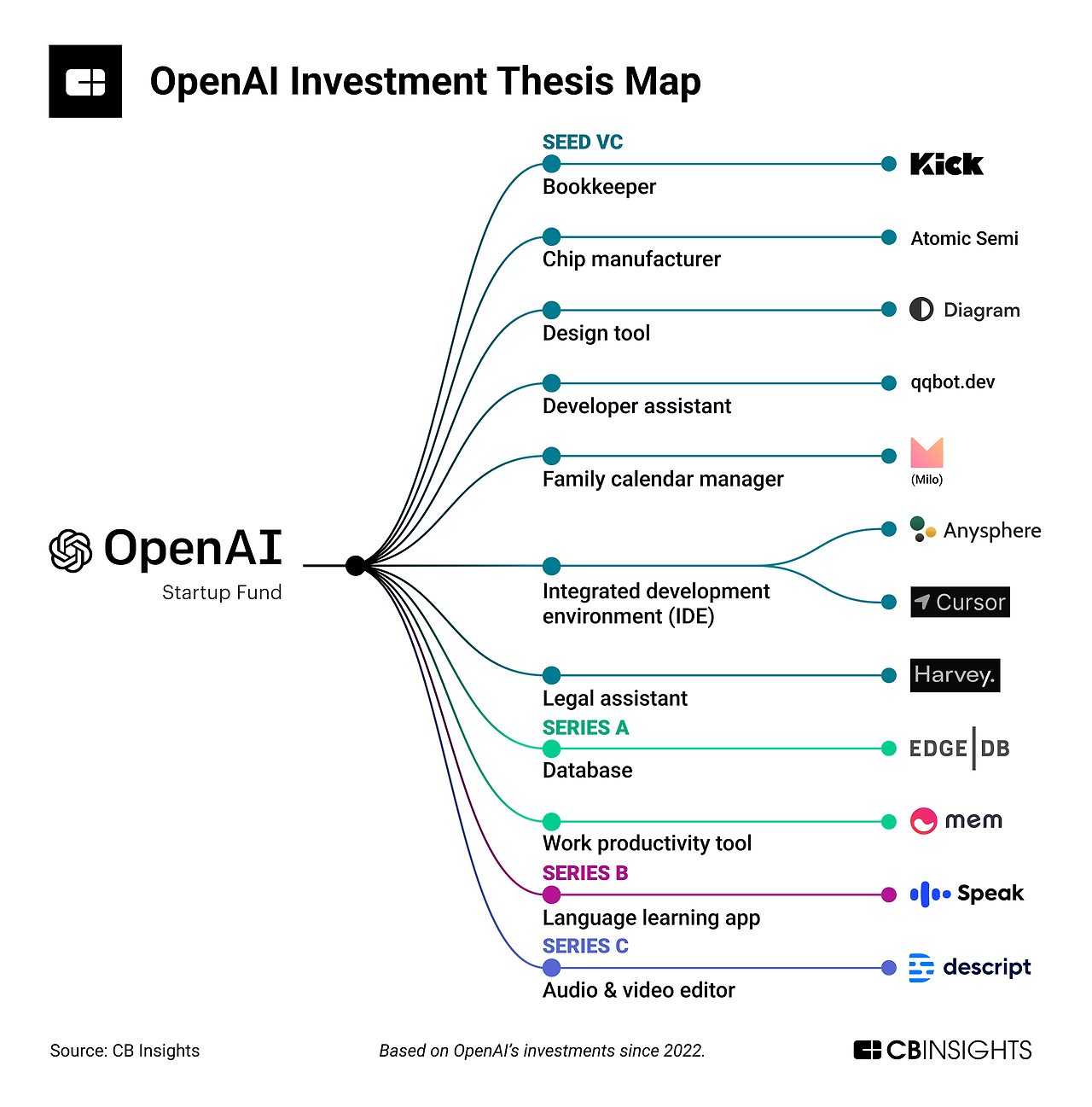
오픈AI가 투자했던 스타트업 일부를 보여주는 그래픽입니다. 저는 개발자 도구 '커서'와 에듀테크 '스픽'이 눈에 띄네요. <출처=CB인사이츠>
여기서 잠깐! 오픈AI가 어떤 회사인지를 알고 넘어가는 것도 중요합니다. 오픈AI는 기본적으로 '인공 일반 지능(AGI)이 모든 인류에게 이익을 주도록 보장한다'는사명을 추구하기 위해 비영리 이사회가 통제하는 이른바 '수익 상한'(capped-profit) 기업이라는 독특한 구조를 채택했습니다. 이 구조는 현재 오픈AI의 기업 전략 전반에 깊은 영향을 미치고 있죠.
한편으로는 장기적이고 자본 집약적인 연구를 추구할 수 있는 자유를 부여하지만, 다른 한편으로는 막대한 컴퓨팅 비용을 충당하기 위해 상당한 수익을 창출해야 하는 필요성을 야기합니다.
서두에서 잠깐 언급한 대로 오픈AI가 성장을 위해 전략적 인수와 벤처 투자에 집중하는 것도 이 때문입니다. 핵심 기술과 관련 인재를 확보하기 위해 아예 해당 회사를 사들이거나 오픈AI 스타트업 펀드를 통해 생태계를 키우는 것! 이는 AI라는 거대한 '엔진'의 성능을 끌어올리는 동시에 그 엔진을 활용한 다양한 '차량'(외부 애플리케이션)이 번성할 수 있는 환경을 조성하는 이중 전략인 셈입니다.
이러한 접근 방식은 단순한 기업 성장을 넘어섭니다. AI 기술 스택의 핵심과 떠오르는 애플리케이션 생태계에 대한 통제권을 확보하려는 정교한 계산이죠. 예를 들어'록셋'(데이터 인프라)이나'스탯시그'(제품 테스트)같은 기업 인수는 핵심 성능 지표에 대한 직접적인 통제권을 부여하고 외부 의존도를 낮춥니다. 동시에 스타트업 펀드는 오픈AI API에 깊숙이 의존하는 기업들에 투자함으로써 높은 전환 비용을 만들고 플랫폼의'고착 효과'를 강화합니다.
이는 과거 마이크로소프트가 운영체제(OS)를 통해 개발자 생태계를 장악하고, 애플이 하드웨어부터 소프트웨어, 앱스토어까지 모두 통제했던 전략과 매우 유사합니다. 결국 오픈AI는 AGI를 구축하는 것을 넘어 스스로가 필수불가결한 중심이 되는 시장을 설계하고 있는 것입니다. (여러분의 생각은 어떠신가요?)
Every token sent through a wrapper — paid or not — earns OpenAI money. Multiply that by millions of freemium users, and these startups become unpaid distribution arms, subsidizing OpenAI’s growth while bleeding out.
래퍼를 통해 전송된 모든 토큰은 유료든 무료든 OpenAI의 수익을 창출합니다. 여기에 수백만 명의 프리미엄(Freemium) 사용자가 더해지면, 이러한 스타트업들은 무료 배포 업체로 전락하여 OpenAI의 성장을 지원하면서도 쇠퇴하는 모습을 보입니다.
OpenAI Python 라이브러리는 Python 3.8 이상 애플리케이션에서 OpenAI REST API에 편리하게 액세스할 수 있도록 합니다. 이 라이브러리는 모든 요청 매개변수와 응답 필드에 대한 유형 정의를 포함하고 있으며,httpx기반 동기 및 비동기 클라이언트를 모두 제공합니다 .
The REST API documentation can be found onplatform.openai.com. The full API of this library can be found inapi.md.
Installation
# install from PyPI
pip install openai
Usage
The full API of this library can be found inapi.md.
The primary API for interacting with OpenAI models is theResponses API. You can generate text from the model with the code below.
import os
from openai import OpenAI
client = OpenAI(
# This is the default and can be omitted
api_key=os.environ.get("OPENAI_API_KEY"),
)
response = client.responses.create(
model="gpt-4o",
instructions="You are a coding assistant that talks like a pirate.",
input="How do I check if a Python object is an instance of a class?",
)
print(response.output_text)
The previous standard (supported indefinitely) for generating text is theChat Completions API. You can use that API to generate text from the model with the code below.
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "developer", "content": "Talk like a pirate."},
{
"role": "user",
"content": "How do I check if a Python object is an instance of a class?",
},
],
)
print(completion.choices[0].message.content)
While you can provide anapi_keykeyword argument, we recommend usingpython-dotenvto addOPENAI_API_KEY="My API Key"to your.envfile so that your API key is not stored in source control.Get an API key here.
import base64
from openai import OpenAI
client = OpenAI()
prompt = "What is in this image?"
with open("path/to/image.png", "rb") as image_file:
b64_image = base64.b64encode(image_file.read()).decode("utf-8")
response = client.responses.create(
model="gpt-4o-mini",
input=[
{
"role": "user",
"content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": f"data:image/png;base64,{b64_image}"},
],
}
],
)
Async usage
Simply importAsyncOpenAIinstead ofOpenAIand useawaitwith each API call:
import os
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
# This is the default and can be omitted
api_key=os.environ.get("OPENAI_API_KEY"),
)
async def main() -> None:
response = await client.responses.create(
model="gpt-4o", input="Explain disestablishmentarianism to a smart five year old."
)
print(response.output_text)
asyncio.run(main())
Functionality between the synchronous and asynchronous clients is otherwise identical.
Streaming responses
We provide support for streaming responses using Server Side Events (SSE).
from openai import OpenAI
client = OpenAI()
stream = client.responses.create(
model="gpt-4o",
input="Write a one-sentence bedtime story about a unicorn.",
stream=True,
)
for event in stream:
print(event)
The async client uses the exact same interface.
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI()
async def main():
stream = await client.responses.create(
model="gpt-4o",
input="Write a one-sentence bedtime story about a unicorn.",
stream=True,
)
async for event in stream:
print(event)
asyncio.run(main())
Realtime API beta
The Realtime API enables you to build low-latency, multi-modal conversational experiences. It currently supports text and audio as both input and output, as well asfunction callingthrough a WebSocket connection.
Under the hood the SDK uses thewebsocketslibrary to manage connections.
The Realtime API works through a combination of client-sent events and server-sent events. Clients can send events to do things like update session configuration or send text and audio inputs. Server events confirm when audio responses have completed, or when a text response from the model has been received. A full event reference can be foundhereand a guide can be foundhere.
Basic text based example:
import asyncio
from openai import AsyncOpenAI
async def main():
client = AsyncOpenAI()
async with client.beta.realtime.connect(model="gpt-4o-realtime-preview") as connection:
await connection.session.update(session={'modalities': ['text']})
await connection.conversation.item.create(
item={
"type": "message",
"role": "user",
"content": [{"type": "input_text", "text": "Say hello!"}],
}
)
await connection.response.create()
async for event in connection:
if event.type == 'response.text.delta':
print(event.delta, flush=True, end="")
elif event.type == 'response.text.done':
print()
elif event.type == "response.done":
break
asyncio.run(main())
However the real magic of the Realtime API is handling audio inputs / outputs, see this exampleTUI scriptfor a fully fledged example.
Realtime error handling
Whenever an error occurs, the Realtime API will send anerroreventand the connection will stay open and remain usable. This means you need to handle it yourself, asno errors are raised directlyby the SDK when anerrorevent comes in.
client = AsyncOpenAI()
async with client.beta.realtime.connect(model="gpt-4o-realtime-preview") as connection:
...
async for event in connection:
if event.type == 'error':
print(event.error.type)
print(event.error.code)
print(event.error.event_id)
print(event.error.message)
Using types
Nested request parameters areTypedDicts. Responses arePydantic modelswhich also provide helper methods for things like:
Serializing back into JSON,model.to_json()
Converting to a dictionary,model.to_dict()
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, setpython.analysis.typeCheckingModetobasic.
Pagination
List methods in the OpenAI API are paginated.
This library provides auto-paginating iterators with each list response, so you do not have to request successive pages manually:
from openai import OpenAI
client = OpenAI()
all_jobs = []
# Automatically fetches more pages as needed.
for job in client.fine_tuning.jobs.list(
limit=20,
):
# Do something with job here
all_jobs.append(job)
print(all_jobs)
Or, asynchronously:
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI()
async def main() -> None:
all_jobs = []
# Iterate through items across all pages, issuing requests as needed.
async for job in client.fine_tuning.jobs.list(
limit=20,
):
all_jobs.append(job)
print(all_jobs)
asyncio.run(main())
Alternatively, you can use the.has_next_page(),.next_page_info(), or.get_next_page()methods for more granular control working with pages:
first_page = await client.fine_tuning.jobs.list(
limit=20,
)
if first_page.has_next_page():
print(f"will fetch next page using these details: {first_page.next_page_info()}")
next_page = await first_page.get_next_page()
print(f"number of items we just fetched: {len(next_page.data)}")
# Remove `await` for non-async usage.
Or just work directly with the returned data:
first_page = await client.fine_tuning.jobs.list(
limit=20,
)
print(f"next page cursor: {first_page.after}") # => "next page cursor: ..."
for job in first_page.data:
print(job.id)
# Remove `await` for non-async usage.
Nested params
Nested parameters are dictionaries, typed usingTypedDict, for example:
Request parameters that correspond to file uploads can be passed asbytes, or aPathLikeinstance or a tuple of(filename, contents, media type).
from pathlib import Path
from openai import OpenAI
client = OpenAI()
client.files.create(
file=Path("input.jsonl"),
purpose="fine-tune",
)
The async client uses the exact same interface. If you pass aPathLikeinstance, the file contents will be read asynchronously automatically.
Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass ofopenai.APIConnectionErroris raised.
When the API returns a non-success status code (that is, 4xx or 5xx response), a subclass ofopenai.APIStatusErroris raised, containingstatus_codeandresponseproperties.
All errors inherit fromopenai.APIError.
import openai
from openai import OpenAI
client = OpenAI()
try:
client.fine_tuning.jobs.create(
model="gpt-4o",
training_file="file-abc123",
)
except openai.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except openai.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except openai.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
Error codes are as follows:
Status CodeError Type
400
BadRequestError
401
AuthenticationError
403
PermissionDeniedError
404
NotFoundError
422
UnprocessableEntityError
429
RateLimitError
>=500
InternalServerError
N/A
APIConnectionError
Request IDs
For more information on debugging requests, seethese docs
All object responses in the SDK provide a_request_idproperty which is added from thex-request-idresponse header so that you can quickly log failing requests and report them back to OpenAI.
response = await client.responses.create(
model="gpt-4o-mini",
input="Say 'this is a test'.",
)
print(response._request_id) # req_123
Note that unlike other properties that use an_prefix, the_request_idpropertyispublic. Unless documented otherwise,allother_prefix properties, methods and modules areprivate.
[!IMPORTANT] If you need to access request IDs for failed requests you must catch theAPIStatusErrorexception
import openai
try:
completion = await client.chat.completions.create(
messages=[{"role": "user", "content": "Say this is a test"}], model="gpt-4"
)
except openai.APIStatusError as exc:
print(exc.request_id) # req_123
raise exc
Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff. Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict, 429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use themax_retriesoption to configure or disable retry settings:
from openai import OpenAI
# Configure the default for all requests:
client = OpenAI(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).chat.completions.create(
messages=[
{
"role": "user",
"content": "How can I get the name of the current day in JavaScript?",
}
],
model="gpt-4o",
)
Timeouts
By default requests time out after 10 minutes. You can configure this with atimeoutoption, which accepts a float or anhttpx.Timeoutobject:
from openai import OpenAI
# Configure the default for all requests:
client = OpenAI(
# 20 seconds (default is 10 minutes)
timeout=20.0,
)
# More granular control:
client = OpenAI(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).chat.completions.create(
messages=[
{
"role": "user",
"content": "How can I list all files in a directory using Python?",
}
],
model="gpt-4o",
)
You can enable logging by setting the environment variableOPENAI_LOGtoinfo.
$ export OPENAI_LOG=info
Or todebugfor more verbose logging.
How to tell whetherNonemeansnullor missing
In an API response, a field may be explicitlynull, or missing entirely; in either case, its value isNonein this library. You can differentiate the two cases with.model_fields_set:
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing.with_raw_response.to any HTTP method call, e.g.,
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.with_raw_response.create(
messages=[{
"role": "user",
"content": "Say this is a test",
}],
model="gpt-4o",
)
print(response.headers.get('X-My-Header'))
completion = response.parse() # get the object that `chat.completions.create()` would have returned
print(completion)
These methods return aLegacyAPIResponseobject. This is a legacy class as we're changing it slightly in the next major version.
For the sync client this will mostly be the same with the exception ofcontent&textwill be methods instead of properties. In the async client, all methods will be async.
A migration script will be provided & the migration in general should be smooth.
.with_streaming_response
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use.with_streaming_responseinstead, which requires a context manager and only reads the response body once you call.read(),.text(),.json(),.iter_bytes(),.iter_text(),.iter_lines()or.parse(). In the async client, these are async methods.
As such,.with_streaming_responsemethods return a differentAPIResponseobject, and the async client returns anAsyncAPIResponseobject.
with client.chat.completions.with_streaming_response.create(
messages=[
{
"role": "user",
"content": "Say this is a test",
}
],
model="gpt-4o",
) as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
The context manager is required so that the response will reliably be closed.
Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
Undocumented endpoints
To make requests to undocumented endpoints, you can make requests usingclient.get,client.post, and other http verbs. Options on the client will be respected (such as retries) when making this request.
If you want to explicitly send an extra param, you can do so with theextra_query,extra_body, andextra_headersrequest options.
Undocumented response properties
To access undocumented response properties, you can access the extra fields likeresponse.unknown_prop. You can also get all the extra fields on the Pydantic model as a dict withresponse.model_extra.
Configuring the HTTP client
You can directly override thehttpx clientto customize it for your use case, including:
import httpx
from openai import OpenAI, DefaultHttpxClient
client = OpenAI(
# Or use the `OPENAI_BASE_URL` env var
base_url="http://my.test.server.example.com:8083/v1",
http_client=DefaultHttpxClient(
proxy="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
You can also customize the client on a per-request basis by usingwith_options():
By default the library closes underlying HTTP connections whenever the client isgarbage collected. You can manually close the client using the.close()method if desired, or with a context manager that closes when exiting.
from openai import OpenAI
with OpenAI() as client:
# make requests here
...
# HTTP client is now closed
Microsoft Azure OpenAI
To use this library withAzure OpenAI, use theAzureOpenAIclass instead of theOpenAIclass.
[!IMPORTANT] The Azure API shape differs from the core API shape which means that the static types for responses / params won't always be correct.
from openai import AzureOpenAI
# gets the API Key from environment variable AZURE_OPENAI_API_KEY
client = AzureOpenAI(
# https://learn.microsoft.com/azure/ai-services/openai/reference#rest-api-versioning
api_version="2023-07-01-preview",
# https://learn.microsoft.com/azure/cognitive-services/openai/how-to/create-resource?pivots=web-portal#create-a-resource
azure_endpoint="https://example-endpoint.openai.azure.com",
)
completion = client.chat.completions.create(
model="deployment-name", # e.g. gpt-35-instant
messages=[
{
"role": "user",
"content": "How do I output all files in a directory using Python?",
},
],
)
print(completion.to_json())
In addition to the options provided in the baseOpenAIclient, the following options are provided:
An example of using the client with Microsoft Entra ID (formerly known as Azure Active Directory) can be foundhere.
Versioning
This package generally followsSemVerconventions, though certain backwards-incompatible changes may be released as minor versions:
Changes that only affect static types, without breaking runtime behavior.
Changes to library internals which are technically public but not intended or documented for external use.(Please open a GitHub issue to let us know if you are relying on such internals.)
Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open anissuewith questions, bugs, or suggestions.