
반응형
캐나다 알버타대 연구진이 최근 ‘인공 신경망’의 한계를 극복하는 방안을 제안하는 논문을 네이처에 발표했습니다. 연구 결과보다 논문에서 정리한 인공 신경망의 한계 부분이 더 눈길을 끌었는데요, 이를 짧게 정리해 보겠습니다.
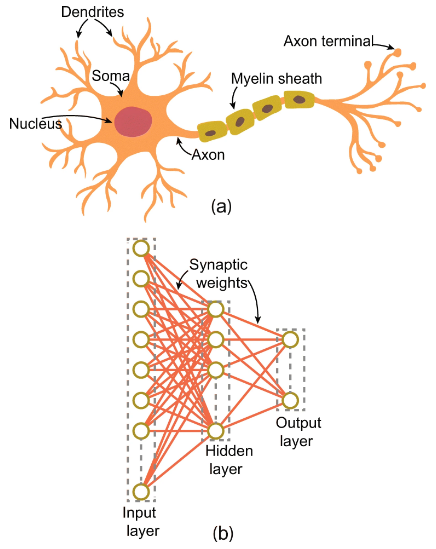
‘신경망’이라는 단어 들어보셨죠? 인간의 두뇌에서 영감을 얻은 일종의 시스템인데요, LLM이 이러한 신경망을 기반으로 구축됐습니다. 신경망은 마치 뇌의 ‘뉴런’이 연결된 것처럼 입력된 데이터를 여러 단계를 거쳐 가중치를 기반으로 답을 내놓는 방식입니다. 뉴런 간의 연결이 탄탄하고 많을수록 뇌 기능이 뛰어나다고 하듯이, 신경망 또한 마찬가지입니다.
신경망에는 입력과 출력 사이에 ‘은닉층’이라는 것이 있는데요, 이곳에서 많은 데이터를 학습하고 계산을 열심히 할수록 좋은 데이터가 나옵니다. 물론 이는 단순화한 설명입니다. 너무 많은 정보를 한 번에 공부하면 뇌에 과부하가 오듯이 은닉층을 늘리기만 하면 오히려 계산이 느려질 수 있다고 해요.
신경망, 정확히 얘기하면 인공 신경망은 이후 머신러닝 분야에서 활발히 적용되고 있습니다. 신경망이 가진 한계도 있습니다. 뇌를 본떴다고는 하지만 생물학적인 뇌와 기계적인 신경망이 같을 리 없는데요, 특히 지속 학습 과정에서 신경망이 가진 단점이 보고되고 있어요.
인간은 이전에 습득한 정보, 지식을 지우지 않고도 새로운 정보에 효과적으로 적응하고 대응할 수 있습니다. 생물체의 신경망은 과거의 데이터를 기억하는 능력, 즉 ‘안정성’과 새로운 개념을 학습하는 능력, ‘가소성’ 사이에서 균형을 찾으면서 학습해 갑니다.
하지만 인공 신경망은 새로운 과제를 학습해야 하는 상황에 직면했을 때 이전에 학습했던 능력을 상실하는 ‘치명적 망각(catastrophic forgetting)’에 취약하다고 해요. 심지어 심할 경우 신경망 자체가 학습 능력을 잃어버린다고 합니다.
알버타대학 연구진의 비유를 볼게요. ‘퐁(Pong)’이라 불리는 비디오게임이 있습니다. 마치 탁구를 하듯 양쪽에서 공을 주고받는 게임인데요, 퐁에서 좋은 성적을 내도록 신경망을 학습시킨 뒤 비행기 게임 ‘갤러그’를 학습시키면 퐁에서의 점수가 크게 하락합니다. 새롭게 학습하는 게임이 많아질수록 처음 학습한 게임 방법을 거의 잃어버리게 됩니다.
반응형
'프로그래밍 > AI_DeepLearning' 카테고리의 다른 글
| AI 코딩 오류, 관리는 인간 프로그래머가 담당해야 (1) | 2024.09.13 |
|---|---|
| 오픈AI “챗GPT 주간활성사용자 2억명”...1년새 100% 성장 (1) | 2024.09.02 |
| 개발 시간을 절반으로 단축하는 25가지 오픈 소스 AI 도구 (0) | 2024.08.27 |
| 국방부, 민간 클라우드로 네이버 선택…메가존이 시스템 구축 (0) | 2024.08.26 |
| HyperCLOVA X Vision: 눈을 뜨다 (2) | 2024.08.26 |