오픈소스 이니셔티브(OSI)는 AI 시스템이 진정한 오픈소스 AI인지 판단하기 위한 참조 기준을 제공한다고 밝혔다.
OSI가 오픈소스 AI 시스템을 정확히 정의하는 표준을 만들기 위해 1년 동안 진행한 글로벌 커뮤니티 이니셔티브의 결과를 지난 28일 발표했다.
노스캐롤라이나주 롤리에서 열린 ‘올 씽스 오픈(All Things Open) 2024’ 컨퍼런스에서 OSI는 ‘오픈소스 AI 정의(OSAID) 버전 1.0’를 공개하며 “오픈소스 정의가 소프트웨어 생태계에서 해왔던 것처럼 허가가 필요 없고, 실용적이며 단순화된 협업을 재창조할 수 있는 원칙을 AI 실무자를 위해 확립하는 프로젝트의 첫 번째 안정 버전”이라고 밝혔다.
마이크로소프트(Microsoft), 구글(Google), 아마존(Amazon), 메타(Meta), 인텔(Intel), 삼성(Samsung) 등 기업의 리더와 모질라 재단(Mozilla Foundation), 리눅스 재단(Linux Foundation), 아파치 소프트웨어 재단(Apache Software Foundation), UN 국제전기통신연합을 포함한 25개 이상의 조직이 공동 설계 과정에 참여한 이 문서는 이미 전 세계 조직으로부터 지지를 받고 있다.
스탠포드대학교 파운데이션 모델 연구센터의 센터장 퍼시 리앙은 성명에서 “데이터에 대한 제약으로 인해 제대로 된 오픈소스 정의를 내리기는 어렵지만, OSI 버전 1.0 정의가 최소한 데이터 처리를 위한 전체 코드(모델 품질의 주요 동인)를 오픈소스로 요구한다는 점을 기쁘게 생각한다”라고 밝혔다. 그는 “핵심은 세부 사항에 있기 때문에, 이 정의를 자체 모델에 적용하는 구체적인 사례가 나온 후에 더 많은 의견을 제시할 수 있을 것”이라고 덧붙였다.
OSI는 자사 방법론이 초기 목적에 부합하는 표준을 만들어냈다고 자신했다.
OSI 이사회 의장인 카를로 피아나는 “오픈소스 AI 정의 1.0으로 이어진 공동 설계 과정은 잘 개발됐고 철저했으며, 포용적이고 공정했다. 이사회가 제시한 원칙을 준수했으며, OSI 리더십과 직원들이 우리 지침을 충실히 따랐다. 이사회는 이 과정을 통해 오픈소스 정의와 자유 소프트웨어 정의에 명시된 기준을 충족하는 결과를 만들어냈다고 확신하며, OSI가 이 정의를 통해 전체 산업에서 의미 있고 실용적인 오픈소스 지침을 제공할 수 있는 위치에 서게 된 것에 매우 고무적이다”라고 강조했다.
오픈소스 AI 시스템의 4가지 기준 오픈소스 AI가 되려면 시스템이 자유 소프트웨어 정의(Free Software Definition)에서 파생된 4가지 기준을 충족해야 한다고 명시됐다. OSAID는 다음과 같이 설명하고 있다.
AI 시스템은 다음과 같은 자유를 부여하는 조건과 방식으로 제공돼야 한다.
• 허가를 구할 필요 없이 어떤 목적으로든 시스템을 사용할 수 있다.
• 시스템의 작동 방식을 연구하고 구성 요소를 검사할 수 있다.
• 출력을 변경하는 것을 포함하여 어떤 목적으로든 시스템을 수정할 수 있다.
• 수정 여부와 관계없이 다른 사람이 어떤 목적으로든 시스템을 공유할 수 있다.
OSAID는 “이 자유는 완전한 기능을 갖춘 시스템과 시스템의 개별 요소 모두에 적용된다. 자유를 행사하기 위한 전제 조건은 시스템을 수정하기 위해 권장되는 양식에 액세스할 권한을 갖는 것이다”라고 언급했다.
또한 OSAID는 머신러닝 시스템을 수정할 때 권장되는 양식을 설명하며, 포함해야 할 데이터 정보, 코드, 매개변수를 명시했다.
그러나 OSAID는 “오픈소스 AI 정의는 모델 매개변수가 모든 사람에게 자유롭게 제공되도록 보장하는 특정 법적 메커니즘을 요구하지 않는다. 본질적으로 자유로울 수도 있고, 자유를 보장하기 위해 라이선스 또는 다른 법적 수단이 필요할 수도 있다. 법률 체계가 오픈소스 AI 시스템을 다룰 기회가 많아지면 더 명확해질 수 있다”라고 설명했다.
자체적인 오픈소스 AI 규정을 갖고 있는 넥스트클라우드(Nextcloud)도 OSAID를 지지하며, 이를 자사의 규정에 통합할 계획이라고 언급했다. 넥스트클라우드의 CEO이자 설립자인 프랭크 칼리체크는 “AI 솔루션 사용자는 투명성과 통제권을 누릴 자격이 있다. 우리가 2023년 초에 윤리적 AI 등급을 도입한 이유다. 이제 기술 대기업들이 오픈소스 AI라는 용어를 악용하려 하는 모습이 목격되고 있다. 사용자와 시장을 보호하기 위해 커뮤니티에서 오픈소스 AI에 대한 명확한 정의를 만드는 일을 전적으로 지지한다”라고 밝혔다.
관련 질문 및 우려 사항 한편 인포테크 리서치 그룹의 수석 연구 책임자인 브라이언 잭슨은 몇 가지 우려 사항을 언급했다.
그는 “오픈소스 AI 표준의 개요를 읽으면서 몇 가지 중요한 질문이 떠올랐다. OSI의 표준은 명확하고 이전의 오픈소스 소프트웨어 공개 표준과 일관된다. AI에는 전통적인 오픈소스 소프트웨어 라이선스가 다루지 않는 훈련 데이터, 모델 가중치, 새로운 아키텍처 등 몇 가지 주요한 차이점이 있기에 표준이 필요하다”라고 말했다.
잭슨은 의료 데이터처럼 법적으로 공개가 불가능한 데이터도 오픈소스가 될 수 있다고 언급했다. OSAID가 학습 데이터의 비공개를 허용하기 때문이다. 그는 “맥락은 이해하지만, 학습 데이터에 저작권 보호 콘텐츠가 포함되는 문제를 해결하지 못한다”라고 지적했다.
또한 그는 딥페이크나 가짜 누드 이미지를 생성하는 ‘누디파이’ 앱과 같은 오픈소스 AI로 인해 발생할 수 있는 피해도 우려했다.
잭슨은 “우리는 이미 오픈소스 AI로 인한 피해 사례를 목격했다”라고 덧붙였다. 그는 “아동 성 착취물(CSAM)은 오픈소스 AI가 악의적으로 사용되는 대표 사례다. 인터넷 감시 재단은 다크웹 포럼에서 이런 자료의 거래 활동이 증가하고 있으며, 제작자들이 더 정확한 결과를 얻기 위해 오픈소스 이미지 생성 모델 사용을 선호한다고 보고한 바 있다. 오픈소스 AI를 사용한 사기도 문제다. 이런 모델은 더 설득력 있는 딥페이크 제작, 피싱 메시지 맞춤화, 취약점이 있는 사용자 자동 검색에 활용되도록 수정될 가능성이 있다”라고 말했다.
반면 공동 설계자들의 우려는 크지 않았다. 모질라에서 AI 전략을 이끄는 아야 브데이르는 “새로운 정의는 오픈소스 모델이 ‘숙련된 사람이 동일하거나 유사한 데이터를 사용해 실질적으로 동등한 시스템을 재현할 수 있을’ 만큼의 학습 데이터 정보를 제공하도록 요구한다. 이는 현재의 독점 또는 표면적인 오픈소스 모델보다 더 진전된 조치다. 이는 AI 학습 데이터를 다루는 작업의 복잡성을 해결하려는 출발점이다. 다시 말해 전체 데이터셋 공유의 어려움을 인정하면서도 개방형 데이터셋을 AI 생태계의 더 일반적인 부분으로 만들기 위한 노력이다. 오픈소스 AI에서 학습 데이터와 관련한 이 관점이 완벽하지는 않겠지만, 실제로 어떤 모델 제작자도 충족하지 못할 이상적이고 순수한 종류의 표준을 고집하면 오히려 역효과를 낳을 수 있다”라고 설명했다.
OSI 자체는 OSAID 버전 1.0에 만족하고 있으며, 이를 향후 작업의 출발점으로 보고 있다.
OSI 총괄 책임자인 스테파노 마풀리는 성명을 통해 “OSAID 버전 1.0이 나오기까지 OSI 커뮤니티는 새로운 도전이 가득한 어려운 여정을 거쳤다. 서로 다른 의견과 미개척 기술 영역, 그리고 때로는 열띤 토론이 있었지만, 그 결과물은 2년간의 과정을 시작할 때 설정한 기대치에 부합한다. 더 넓은 오픈소스 커뮤니티와 함께 OSAID 버전 1.0을 이해하고 적용할 수 있는 지식을 개발하면서 점차 정의를 개선해 나가기 위해 지속적으로 노력하겠다는 첫걸음이다”라고 밝혔다.
Each ML/AI project stakeholder requires specialized tools that efficiently enable them to manage the various stages of an ML/AI project, from data preparation and model development to deployment and monitoring. They tend to use specialized open source tools because oftheir contribution as a significant catalyst to the advancement, development, and ease of AI projects. As a result, numerous open source AI tools have emerged over the years, making it challenging to pick from the available options.
This article highlights some factors to consider when picking open source tools and introduces you to 25 open-source options that you can use for your AI project.
Picking open source tools for AI project
The open source tooling model has allowed companies to develop diverse ML tools to help you handle particular problems in an AI project. The AI tooling landscape is already quite saturated with tools, and the abundance of options makes tool selection difficult. Some of these tools even provide similar solutions. You may be tempted to lean toward adopting tools just because of the enticing features they present. However, there are other crucial factors that you should consider before selecting a tool, which include:
Popularity
Impact
Innovation
Community engagement
Relevance to emerging AI trends.
Popularity
Widely adopted tools often indicate active development, regular updates, and strong community support, ensuring reliability and longevity.
Impact
A tool with a track record of addressing pain points, delivering measurable improvements, providing long-term project sustainability, and adapting to evolving needs of the problems of an AI project is a good measure of an impactful tool that stakeholders are interested in leveraging.
Innovation
Tools that embrace more modern technologies and offer unique features demonstrate a commitment to continuous improvement and have the potential to drive advancements and unlock new possibilities.
Community engagement
Active community engagement fosters collaboration, provides support, and ensures a tool's continued relevance and improvement.
Relevance to emerging AI trends
Tools aligned with emerging trends like LLMs enable organizations to leverage the latest capabilities, ensuring their projects remain at the forefront of innovation.
25 open source tools for your AI project
Based on these factors, here are 25 tools that you and the different stakeholders on your team can use for various stages in your AI project.
1. KitOps
Multiple stakeholders are involved in the machine learning development lifecycle which requires different MLOps tools and environments at various stages of the AI project., which makes it hard to guarantee an organized, portable, transparent, and secure model development pipeline.
This introduces opportunities for model lineage breaks and accidental or malicious model tampering or modifications during model development. Since the contents of a model are a "black box”—without efficient storage and lineage—it is impossible to know if a model's or model artifact's content has been tampered with between model development, staging, deployment, and retirement pipelines.
KitOpsprovides AI project stakeholders with a secure package called ModelKit that they can use to share and manage models, code, metadata, and artifacts throughout the ML development lifecycle.
The ModelKit is an immutable OCI-standard artifact that leverages normal container-native technologies (similar to Docker and Kubernetes), making them seamlessly interoperable and portable across various stakeholders using common software tools and environments. As an immutable package, ModelKit is tamper-proof. This tamper-proof property provides stakeholders with a versioning system that tracks every single update to any of its content (i.e., models, code, metadata, and artifacts) throughout the ML development and deployment pipelines.
2. LangChain
LangChainis a machine learning framework that enables ML engineers and software developers to build end-to-end LLM applications quickly. Its modular architecture allows them to easily mix and match itsextensive suite of componentsto create custom LLM applications.
LangChain simplifies the LLM application's development and deployment stages with its ecosystem of interconnected parts, consisting ofLangSmith,LangServe, andLangGraph. Together, they enable ML engineers and software developers to build robust, diverse, and scaleable LLM applications efficiently.
LangChain enables professionals without a strong AI background to easily build an application with large language models (LLMs).
3. Pachyderm
Pachydermis a data versioning and management platform that enables engineers to automate complex data transformations. It uses a data infrastructure that provides data lineage via a data-driven versioning pipeline. The version-controlled pipelines are automatically triggered based on changes in the data. It tracks every modification to the data, making it simple to duplicate previous results and test with various pipeline versions.
Pachyderm's data infrastructure provides "data-aware" pipelines with versioning and lineage.
4. ZenML
ZenMLis a structured MLOps framework that abstracts the creation of MLOps pipelines, allowing data scientists and ML engineers to focus on the core steps of data preprocessing, model training, evaluation, and deployment without getting bogged down in infrastructure details.
ZenML framework abstracts MLOps infrastructure complexities and simplifies the adoption of MLOps, making the AI project components accessible, reusable, and reproducible.
5. Prefect
Prefectis an MLOps orchestration framework for machine learning pipelines. It uses the concepts of tasks (individual units of work) and flows (sequences of tasks) to construct an ML pipeline for running different steps of an ML code, such as feature engineering and training. This modular structure enables ML engineers to simplify creating and managing complex ML workflows.
Prefect simplifies data workflow management, robust error handling, state management, and extensive monitoring.
6. Ray
Rayis a distributed computing framework that makes it easy for data scientists and ML engineers to scale machine learning workloads during model development. It simplifies scaling computationally intensive workloads, like loading and processing extensive data or deep learning model training, from a single machine to large clusters.
Ray's core distributed runtime, making it easy to scale ML workloads.
7. Metaflow
Metaflowis an MLOps tool that enhances the productivity of data scientists and ML engineers with a unified API. The API offers a code-first approach to building data science workflows, and it contains the wholeinfrastructure stackthat data scientists and ML engineers need to execute AI projects from prototype to production.
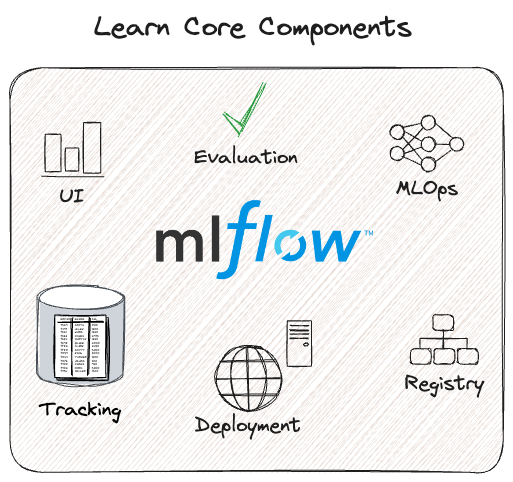
8. MLflow
MLflowallows data scientists and engineers to manage model development and experiments. It streamlines your entire model development lifecycle, from experimentation to deployment.
MLflow’s key features include: MLflow tracking:It provides an API and UI to record and query your experiment, parameters, code versions, metrics, and output files when training your machine learning model. You can then compare several runs after logging the results.
MLflow projects:It provides a standard reusable format to package data science code and includes API and CLI to run projects to chain into workflows. Any Git repository / local directory can be treated as an MLflow project.
MLflow models:It offers a standard format to deploy ML models in diverse serving environments.
MLflow model registry:It provides you with a centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of a model. It also enables model lineage (from your model experiments and runs), model versioning, and development stage transitions (i.e., moving a model from staging to production).
9. Kubeflow
Kubeflowis an MLOps toolkit for Kubernetes. It is designed to simplify the orchestration and deployment of ML workflows on Kubernetes clusters. Its primary purpose is to make scaling and managing complex ML systems easier, portable, and scalable across different infrastructures.
Kubeflow is a key player in the MLOps landscape, and it introduced a robust and flexible platform for building, deploying, and managing machine learning systems on Kubernetes. This unified platform for developing, deploying, and managing ML models enables collaboration among data scientists, ML engineers, and DevOps teams.
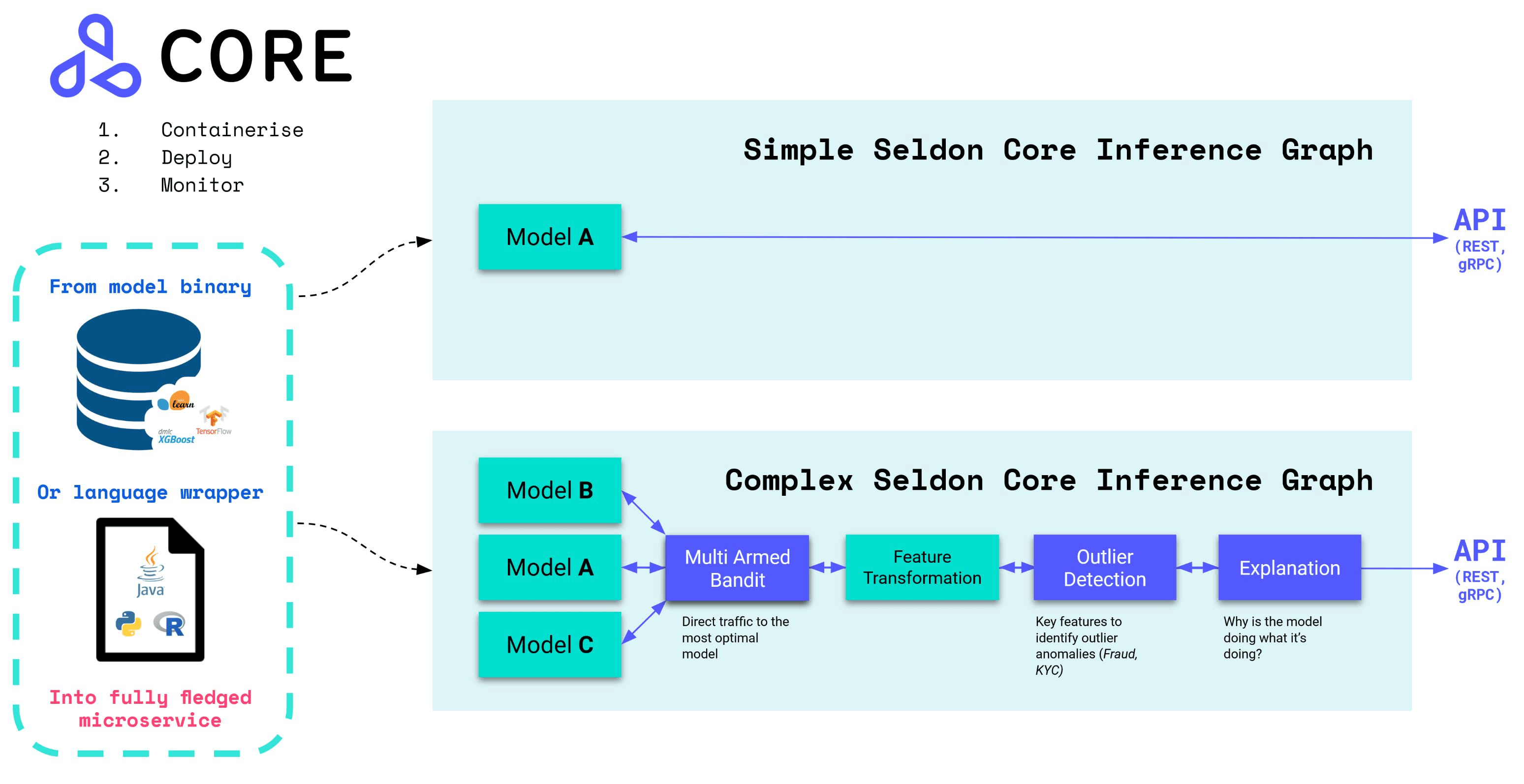
10. Seldon core
Seldon coreis an MLOps platform that simplifies the deployment, serving, and management of machine learning models by converting ML models (TensorFlow, PyTorch, H2o, etc.) or language wrappers (Python, Java, etc.) into production-ready REST/GRPC microservices. Think of them as pre-packaged inference servers or custom servers. Seldon core also enables the containerization of these servers and offers out-of-the-box features like advanced metrics, request logging, explainers, outlier detectors, A/B tests, and canaries.
Seldon Core's solution focuses on model management and governance. Its adoption is geared toward ML and DevOps engineers, specifically for model deployment and monitoring, instead of small data science teams.
11. DVC (Data Version Control)
Implementing version control for machine learning projects entails managing both code and the datasets, ML models, performance metrics, and other development-related artifacts. Its purpose is to bring the best practices from software engineering, like version control and reproducibility, to the world of data science and machine learning.DVCenables data scientists and ML engineers to track changes to data and models like Git does for code, making it able to run on top of any Git repository. It enables the management of model experiments.
DVC's integration with Git makes it easier to apply software engineering principles to data science workflows.
12. Evidently AI
EvidentlyAIis an observability platform designed to analyze and monitor production machine learning (ML) models. Its primary purpose is to help ML practitioners understand and maintain the performance of their deployed models over time. Evidently provides a comprehensive set of tools for tracking key model performance metrics, such as accuracy, precision, recall, and drift detection. It also enables stakeholders to generate interactive reports and visualizations that make it easy to identify issues and trends.
13. Mage AI
Mage AIis a data transforming and integrating framework that allows data scientists and ML engineers to build and automate data pipelines without extensive coding. Data scientists can easily connect to their data sources, ingest data, and build production-ready data pipelines within Mage notebooks.
14. ML Run
ML Runprovides a serverless technology for orchestrating end-to-end MLOps systems. The serverless platform converts the ML code into scalable and managed microservices. This streamlines the development and management pipelines of the data scientists, ML, software, and DevOps/MLOps engineers throughout the entire machine learning (ML) lifecycle, across their various environments.
15. Kedro
Kedrois an ML development framework for creating reproducible, maintainable, modular data science code. Kedro improves AI project development experience via data abstraction and code organization. Using lightweight data connectors, it provides a centralized data catalog to manage and track datasets throughout a project. This enables data scientists to focus on building production level code through Kedro's data pipelines, enabling other stakeholders to use the same pipelines in different parts of the system.
Kedro focuses on data pipeline development by enforcing SWE best practices for data scientists.
16. WhyLogs
WhyLogsby WhyLabs is an open-source data logging library designed for machine learning (ML) models and data pipelines. Its primary purpose is to provide visibility into data quality and model performance over time.
With WhyLogs, MLOps engineers can efficiently generate compact summaries of datasets (called profiles) that capture essential statistical properties and characteristics. These profiles track changes in datasets over time, helping detect data drift – a common cause of model performance degradation. It also provides tools for visualizing key summary statistics from dataset profiles, making it easy to understand data distributions and identify anomalies.
17. Feast
Defining, storing, and accessing features for model training and online inference in silos (i.e., from different locations) can lead to inconsistent feature definitions, data duplication, complex data access and retrieval, etc.Feastsolves the challenge of stakeholders managing and serving machine learning (ML) features in development and production environments.
Feast is a feature store that bridges the gap between data and machine learning models. It provides a centralized repository for defining feature schemas, ensuring consistency across different teams and projects. This can ensure that the feature values used for model inference are consistent with the state of the feature at the time of the request, even for historical data.
Feast is a centralized repository for managing, storing, and serving features, ensuring consistency and reliability across training and serving environments.
18. Flyte
Data scientists and data and analytics pipeline engineers typically rely on ML and platform engineers to transform models and training pipelines into production-ready systems.
Flyteempowers data scientists and data and analytics engineers with the autonomy to work independently. It provides them with a Python SDK for building workflows, which can then be effortlessly deployed to the Flyte backend. This simplifies the development, deployment, and management of complex ML and data workflows by building and executing reliable and reproducible pipelines at scale.
19. Featureform
The ad-hoc practice of data scientists developing features for model development in isolation makes it difficult for other AI project stakeholders to understand, reuse, or build upon existing work. This leads to duplicated effort, inconsistencies in feature definitions, and difficulties in reproducing results.
Featureformis a virtual feature store that streamlines data scientists' ability to manage and serve features for machine learning models. It acts as a "virtual" layer over existing data infrastructure like Databricks and Snowflake. This allows data scientists to engineer and deploy features directly to the data infrastructure for other stakeholders. Its structured, centralized feature repository and metadata management approach empower data scientists to seamlessly transition their work from experimentation to production, ensuring reproducibility, collaboration, and governance throughout the ML lifecycle.
20. Deepchecks
Deepchecksis an ML monitoring tool for continuously testing and validating machine learning models and data from an AI project's experimentation to the deployment stage. It provides a wide range of built-in checks to validate model performance, data integrity, and data distribution. These checks help identify issues like model bias, data drift, concept drift, and leakage.
21. Argo
Argoprovides a Kubernetes-native workflow engine for orchestrating parallel jobs on Kubernetes. Its primary purpose is to streamline the execution of complex, multi-step workflows, making it particularly well-suited for machine learning (ML) and data processing tasks. It enables ML engineers to define each step of the ML workflow (data preprocessing, model training, evaluation, deployment) as individual containers, making it easier to manage dependencies and ensure reproducibility.
Argo workflows are defined using DAGs, where each node represents a step in the workflow (typically a containerized task), and edges represent dependencies between steps. Workflows can be defined as a sequence of tasks (steps) or as a Directed Acyclic Graph (DAG) to capture dependencies between tasks.
22. Deep Lake
Deep Lake(formerly Activeloop Hub) is an ML-specific database tool designed to act as a data lake for deep learning and a vector store for RAG applications. Its primary purpose is accelerating model training by providing fast and efficient access to large-scale datasets, regardless of format or location.
23. Hopsworks feature store
Advanced MLOps pipelines with at least anMLOps maturity level 1architecture require a centralized feature store.Hopsworksis a perfect feature store for such architecture. It provides an end-to-end solution for managing ML feature lifecycle, from data ingestion and feature engineering to model training, deployment, and monitoring. This facilitates feature reuse, consistency, and faster model development.
24. NannyML
NannyMLis a Python library specialized in post-deployment monitoring and maintenance of machine learning (ML) models. It enables data scientists to detect and address silent model failure, estimate model performance without immediate ground truth data, and identify data drift that might be responsible for performance degradation.
25. Delta Lake
Delta Lakeis a storage layer framework that provides reliability to data lakes. It addresses the challenges of managing large-scale data in lakehouse architectures, where data is stored in an open format and used for various purposes, like machine learning (ML). Data engineers can build real-time pipelines or ML applications using Delta Lake because it supports both batch and streaming data processing. It also brings ACID (atomicity, consistency, isolation, durability) transactions to data lakes, ensuring data integrity even with concurrent reads and writes from multiple pipelines.
Considering factors like popularity, impact, innovation, community engagement, and relevance to emerging AI trends can help guide your decision when picking open source AI/ML tools, especially for those offering the same value proposition. In some cases, such tools may have different ways of providing solutions for the same use case or possess unique features that make them perfect for a specific project use case.
오픈소스 소프트웨어(OSS)는혁명을 일으켰다오늘날 소프트웨어 개발이 수행되는 방식.수백만 개의 오픈 소스 GitHub 프로젝트를 사용할 수 있으므로 필요에 맞는 최고의 오픈 소스 프로젝트를 탐색하고 찾는 것이 어려울 수 있습니다.
이 기사에는 알아야 할 가장 빠르게 성장하는 오픈 소스 GitHub 리포지토리 상위 10개가 나열되어 있습니다.
1. RLHF + PaLM: 오픈 소스 ChatGPT 대안
PaLM-rlhf-pytorch: 오픈 소스 ChatGPT 대안
RLHF + PaLM repo는 Reinforcement Learning with Human Feedback(RLHF) 및 PaLM 아키텍처를 결합한 진행 중인 구현입니다.ChatGPT와 유사하지만 PaLM 아키텍처의 이점이 추가된 모델의 오픈 소스 버전을 만드는 것을 목표로 합니다.안타깝게도 이 솔루션에 대해 사전 학습된 모델이 제공되지 않습니다.
신인으로서 RATH는 GitHub에서 가장 빠르게 성장하는 커뮤니티 중 하나입니다.최첨단 기술과 데이터 분석 및 시각화에 대한 혁신적인 접근 방식을 통해 RATH는 데이터 전문가와 매니아 사이에서 빠르게 인기를 얻었습니다.
RATH GitHub 스타 히스토리
RATH의 커뮤니티는 개발자, 데이터 과학자 및 비즈니스 분석가 모두 개발에 기여하고 잠재력을 극대화하는 방법에 대한 아이디어를 공유하면서 빠르게 성장하고 있습니다.노련한 데이터 분석가이든 막 시작하든 관계없이 RATH는 데이터 분석 및 시각화 기술을 향상시키려는 모든 사람에게 필수 도구입니다.
Gogs는 Git 버전 제어를 위한 사용자 친화적인 인터페이스를 제공하므로 GitHub의 훌륭한 대안이 됩니다.이슈 추적, 풀 리퀘스트, 위키를 포함한 다양한 기능을 제공합니다.자체 호스팅 및 사용자 정의가 가능한 Gogs는 Git 협업을 위한 유연하고 안전한 솔루션을 제공합니다.
NocoDB는 SQL, NoSQL 및 Graph 데이터베이스를 지원하는 유연하고 확장 가능한 데이터 플랫폼을 제공합니다.데이터베이스 생성 및 관리를 위한 간단하면서도 강력한 인터페이스를 제공하며 실시간 데이터 업데이트를 지원합니다.NocoDB는 데이터에 대한 더 많은 제어 및 사용자 지정이 필요한 사람들을 위한 Airtable의 훌륭한 대안입니다.
Rocket.Chat은 음성 및 화상 통화, 화면 공유, 파일 공유 등 다양한 기능을 통해 실시간 팀 커뮤니케이션을 제공합니다.고도로 사용자 정의가 가능하며 자체 호스팅하거나 클라우드 기반 솔루션으로 사용할 수 있습니다.강력한 협업 도구를 갖춘 Rocket.Chat은 Slack의 훌륭한 대안입니다.
Airbyte는 데이터 통합을 위한 간단하면서도 강력한 인터페이스를 제공합니다.데이터베이스, SaaS 애플리케이션 및 API를 포함한 광범위한 데이터 소스를 지원합니다.실시간 데이터 전송 기능과 유연한 데이터 변환 옵션을 통해 Airbyte는 필요한 곳에 데이터를 쉽게 가져올 수 있습니다.
Supabase는 백엔드 데이터베이스, API 및 실시간 데이터 계층을 통해 웹 애플리케이션을 구축하고 호스팅하기 위한 완벽한 플랫폼을 제공합니다.애플리케이션 생성 및 관리를 위한 간단하고 직관적인 인터페이스를 제공하며 팀을 위한 강력한 협업 도구를 제공합니다.다양한 다른 도구와 확장 및 통합할 수 있는 기능을 갖춘 Supabase는 Firebase의 훌륭한 대안입니다.
KDenLive는 고품질 비디오 콘텐츠를 생성, 편집 및 생산하기 위한 강력하고 유연한 플랫폼을 제공하는 오픈 소스 비디오 편집 소프트웨어입니다.다양한 형식을 지원하며 다중 트랙 편집, 색상 보정, 시각 효과와 같은 고급 기능을 포함합니다.사용자 친화적인 인터페이스와 활발한 커뮤니티를 갖춘 KDenLive는 아마추어 및 전문 비디오 편집자 모두에게 탁월한 선택입니다.
Mastodon은 Twitter와 같은 중앙 집중식 소셜 미디어 플랫폼에 대한 오픈 소스 대안입니다.사용자가 서로 연결하고 콘텐츠를 공유하며 온라인 커뮤니티에 참여할 수 있도록 하는 분산형 서버 네트워크입니다.업데이트 게시, 이미지 및 비디오 공유, 좋아요, 댓글 및 재게시를 통해 다른 사용자와 상호 작용하는 기능을 포함하여 기존 소셜 미디어 플랫폼과 동일한 많은 기능을 제공합니다.Mastodon은 개인 정보 보호, 언론의 자유, 온라인 신원에 대한 통제를 강조하므로 이러한 원칙을 중시하는 사용자에게 인기 있는 선택입니다.
결론적으로 이 10개의 오픈 소스 GitHub 리포지토리는 활기차고 번성하는 오픈 소스 커뮤니티에 대한 증거입니다.독점 솔루션에 대한 비용 효율적인 대안을 제공하고 개발자, 데이터 분석가 및 비즈니스 모두에게 유용한 도구를 제공합니다.오픈 소스의 장점을 활용하여 이 10개 프로젝트는 강력하고 효과적인 솔루션을 개발했으며 확실히 탐색하고 지원할 가치가 있는 중요한 자산입니다.
개발자 콘퍼런스에서 표면적으로 얻을 수 있는 건 물론 ‘개발에 대한 지식’이지만 지식은 구글 검색, 블로그, 스택오버플로우에서 충분히 얻을 수 있다. 컨퍼런스의 슬라이드와 동영상이 공개되니 ‘지식’은 꼭 참여하지 않더라도 얻을 수 있다. 컨퍼런스에서 얻을 수 있는 가장 큰 것은 나 외에도 파이썬과 개발을 좋아하고 즐겁게 사용하고 있는 사람들과 함께한다는 느낌을 받을 수 있다는 점 아닐까. 자신이 좋아하는 것들에 관해서 이야기하는 것을 통해 사람들과 소통할 수 있다는 점도 그렇다. 파이콘에서 이야기를 나눈 한 스피커 분은 한국에 파이썬 하는 사람이 이렇게 많은지 몰랐다며 즐거운 축제 분위기라 너무나 즐거운 행사였다고 했다. 그런 느낌을 많은 분이 받았으면 좋겠다. 다 같이 하는 느낌, 축제에서 즐겁게 이야기하는 느낌 말이다.
파이콘은 돈을 내고 세션을 듣고 집에 가는 행사가 아니다. 누구나 주제를 제안하고 만나서 이야기할 수 있는 열린 공간, 누구나 제안해서 5분짜리 이야기를 할 수 있는 라이트닝 토크는 물론 기념품 가방의 내용물을 채우는 작업도 참석자 모두가 할 수 있도록 모두가 준비해서 함께 만들어나가는 행사가 파이콘이다. 파이콘 한국은 준비하는 사람들이 100% 자발적인 노력을 통해 준비하기 때문에 완성도가 조금 부족한 부분이 있을지 몰라도 더 즐거운 행사가 되지 않았나 싶다.
위에 언급한 프로그램들처럼 파이콘 한국 준비위원회는 파이콘 한국을 더 의미 있는 행사로 만들기 위한 새로운 시도를 계속 하고 있다. 이런 새로운 시도가 파이콘 한국이 자발적인 노력만으로 계속될 수 있는 원동력이라고 생각한다. 새로운 것을 시도하지 않고 해마다 같은 행사를 같은 프로그램으로 한다면 준비하는 사람들이 준비하는 의미와 재미가 없어지지 않을까. 지금까지 한국에서 많은 좋은 커뮤니티 컨퍼런스가 생기고 또 없어지기도 했다. 그 컨퍼런스들은 왜 없어졌을까? 파이콘 한국은 어떻게 이렇게 빠르게 규모와 완성도 면에서 성장할 수 있었고 이런 추세는 언제까지 계속될 수 있을까? 명확한 답이 없는 이 질문을 끊임없이 해가면서 내년에도 파이콘 한국은 계속될 것이다.