
반응형

https://streamlit.io/
streamlit
A faster way to build and share data apps
pypi.org
https://pypi.org/project/streamlit/
Streamlit • A faster way to build and share data apps
Streamlit is an open-source Python framework for machine learning and data science teams. Create interactive data apps in minutes.
streamlit.io
https://pyscript.com/
PyScript
pyscript.com
What is Streamlit?
Streamlit lets you transform Python scripts into interactive web apps in minutes, instead of weeks. Build dashboards, generate reports, or create chat apps. Once you’ve created an app, you can use our Community Cloud platform to deploy, manage, and share your app.
Why choose Streamlit?
- Simple and Pythonic: Write beautiful, easy-to-read code.
- Fast, interactive prototyping: Let others interact with your data and provide feedback quickly.
- Live editing: See your app update instantly as you edit your script.
- Open-source and free: Join a vibrant community and contribute to Streamlit's future.
Installation
Open a terminal and run:
$ pip install streamlit
$ streamlit hello
ctrl + C : 웹서버 shutdown

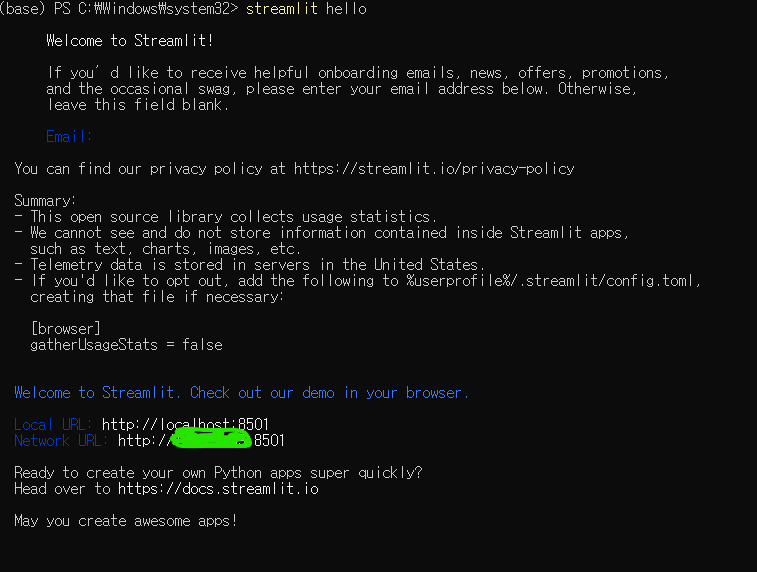
.
반응형
'프로그래밍 > Python' 카테고리의 다른 글
| [python] 생성된 엑셀을 Frequency 순으로, 동일 Frequency 이면 단어순으로 정렬 (0) | 2024.05.02 |
|---|---|
| [python] 웹 기반 파이썬 데이터 앱 쉽게 다루는 스트림릿(Streamlit) 간단 예제 (1) | 2024.04.23 |
| [PYTHON] Lambda function (0) | 2024.04.05 |
| [python] pip install prettytable, 표 형태로 데이터를 보여준다. (0) | 2024.03.25 |
| [python] 한글 자음 확인해서 치환하기 (0) | 2024.03.22 |










