
반응형
https://codecrazypy.blogspot.com/2023/03/python-mcqs-quiz-1.html
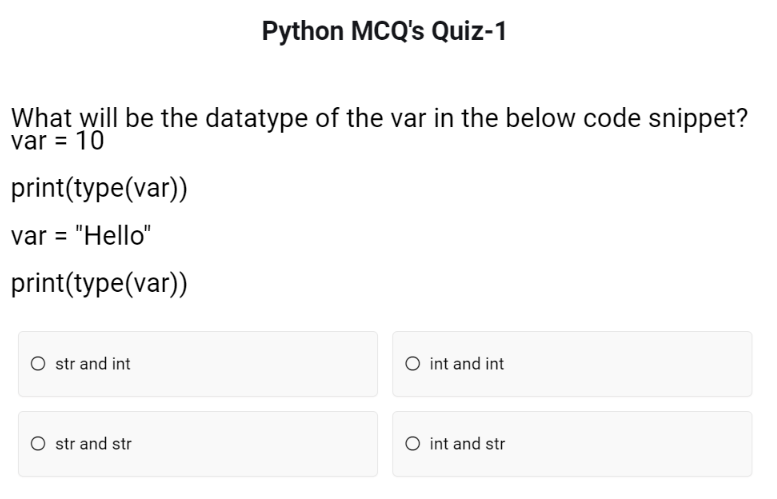
Python MCQ's Quiz-1
Here you can find some infomation about exams,educational events and how to prepare for competitive exams likes ssc gd, railway exams,
codecrazypy.blogspot.com
What will be the datatype of the var in the below code snippet?
var = 10
print(type(var))
var = "Hello"
print(type(var))
반응형
'프로그래밍 > Python' 카테고리의 다른 글
| [python] swapping variables, Flattening a list of lists (0) | 2023.04.18 |
|---|---|
| Python Script to Shutdown Computer (0) | 2023.04.17 |
| [python] 구문 퀴즈, 파이썬 (0) | 2023.03.29 |
| [python] 구문 퀴즈, 파이썬 (0) | 2023.03.23 |
| [PYTHON] 모듈 예제, 모듈 불러오기- 파이썬 (0) | 2023.03.21 |
