40 High Quality Photoshop Web Layout Tutorials
Don't Forget to participate in a contest where you can win the world's biggest UI elements pack "Impressionist User Interface Elements Pack" for 3 winners (1 developer license and 2 personal license) to design your project more creatively.
In this collection, you will discover some useful Photoshop tutorials on creating appealing and excellent website layouts. Creating visually appealing website layouts is very important for every web designs, and Photoshop is the most useful tool for creating such layouts. Keeping this in mind, we thought to compile some useful tutorials that will guide you through the process behind creating web layouts in Photoshop.
As we have already published a post about Photoshop Tutorials for Website Layouts and that was greatly appreciated by our readers. Now we have gathered another great collection of some Photoshop Tutorials for Website Layouts.
Let us take a look at this collection and get some useful insight of how you can also create appealing website layouts for your website. We hope that you will like this collection. Enjoy!
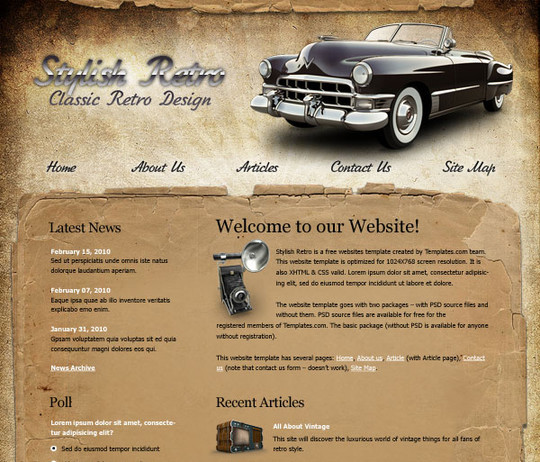
We Go Retro Create Stylish Retro Website Template Using Photoshop
Follow the steps of this tutorial and you’ll learn the designing tips and tricks of this elegant template. This is the advanced level tutorial.
Create a Sleek, High-End Web Design from Scratch
In this tutorial, we’ll put together a high-end Web design using a crisp, thin font, gorgeous background images, and clever use of space and layout. You can easily use the technique to create your own unique designs.
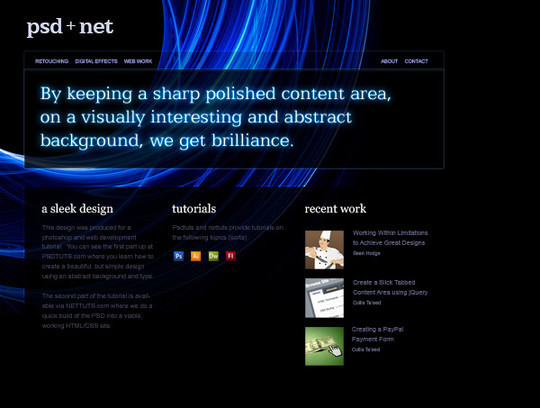
Create a Professional Web 2.0 Layout
In this Photoshop tutorial we’re going to learn how to create a web 2.0 layout, As we go through the tutorial we’ll deal with so many Photoshop techniques. Seems kind of long? that’s because it’s very detailed. I assure you’ll find easy to follow and to get done, just give it a try!

Deep in Space Portfolio Layout Design in Photoshop
In this tutorial we will teach you how to create an outer space website layout that could be used for a portfolio design. If you have any questions about this tutorial be sure to ask in the comments. Also, remember with all the tutorials, the psd is available for download.

How to Make a Highly-Textured Site Layout in Photoshop
In this tutorial, we’ll create a textured site layout by layering multiple images. Creating highly-textured web design layouts is easier than you may think. You can learn to build image intensive designs rapidly. For intermediate Photoshop designers creating this design will take less than an hour, and you’ll learn some professional tips along the way. Let’s get started!

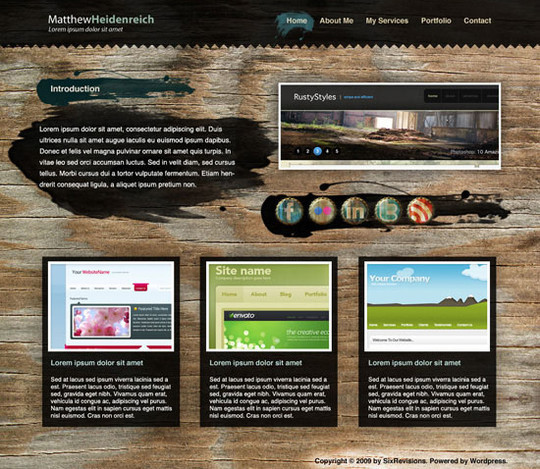
Create a Wooden Grunge Portfolio Web Layout in Photoshop
In this beginner-level web design tutorial, we will show you how to construct a portfolio web layout that has a fixed wooden background with Photoshop. We’ll also use some brushes to accent the design.
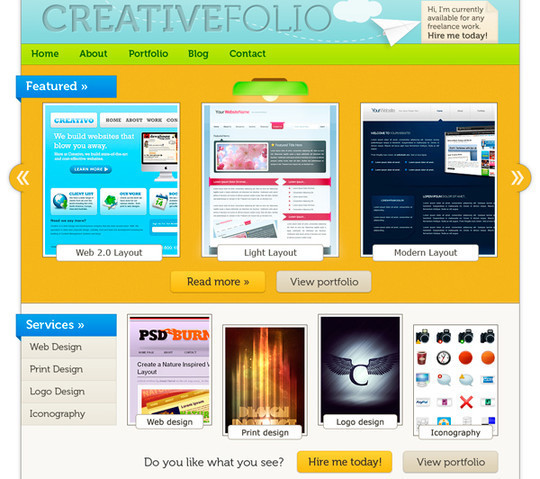
How to Make a Vibrant Portfolio Web Design in Photoshop
In this web design tutorial, we will create a beautiful and colorful portfolio layout using Photoshop. We will show you many techniques for creating different things like bended paper corners, dashed lines, image carousels, 3D bars, and more! We will walk you through each step in exact detail so you won’t be left guessing how to do a certain technique. We will use the 960 Grid System to create this layout.
Design a Clean Mobile App Website in Photoshop
In this tutorial i would like to show you how to create a clean mobile app website in Photoshop. You will see how to create a detailed background, trendy call to action buttons and how to stylize web typography. Hope you will find this tutorial useful and you will learn something new. Please share your opinion about this tutorial in comments section below.
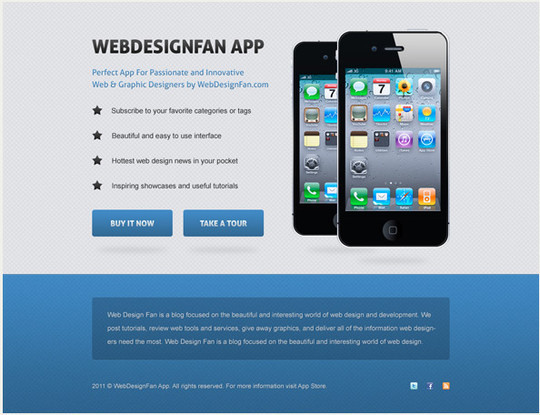
Create a Minimal Resume Website Design in Photoshop
In this tutorial you will learn how to create a minimal resume website design in Photoshop. We will be using simple techniques to achieve clean and professional final result. You will discover how to create simple detailed background, trendy 3D elements also you will see how to effectively stylize web typography.
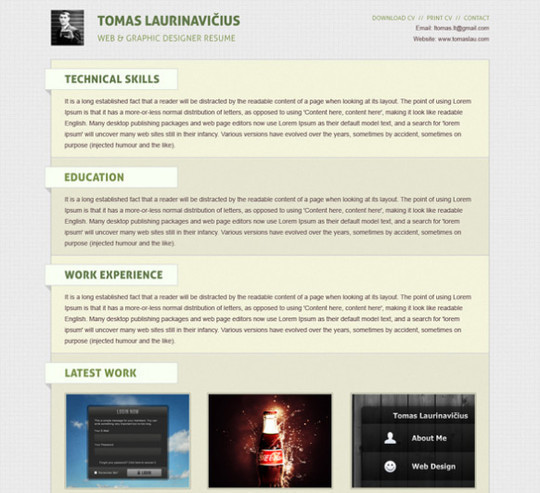
Create an Awesome Black Portfolio Layout
Here we will show you how to create a nice portfolio layout. It will have a nice 2.0 look. More and more webmasters are aiming to create simple layouts. The scope of web 2.0 layouts is that users will see faster what you want to offer
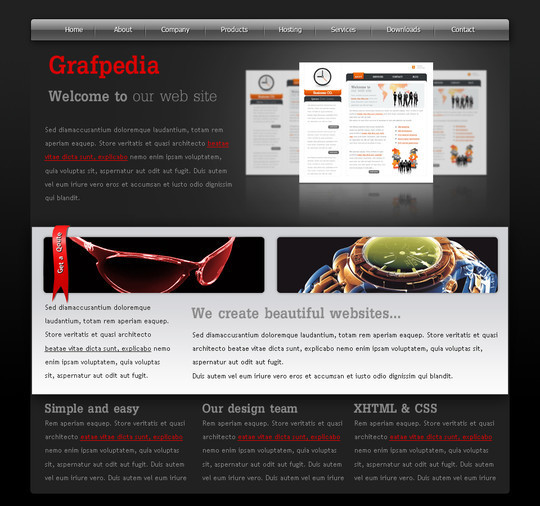
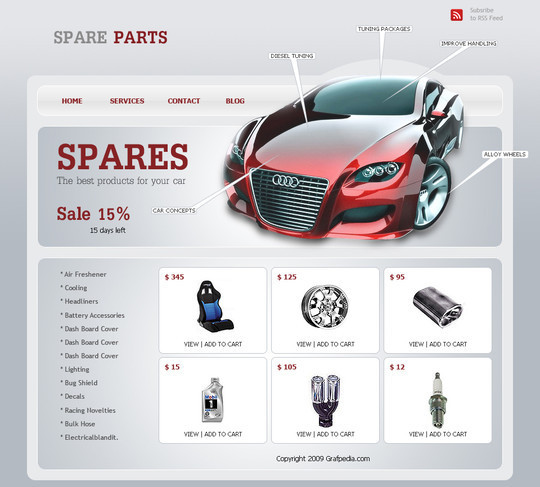
Create an Ecommerce Web Layout
In this tutorial we will create a spare parts ecommerce layout. It can be used for magento, oscommerce, or any e-commerce cms you want.
Create a Grungy, Translucent Web Portfolio Design
In this tutorial you will learn how to create a Grungy, Translucent Web Portfolio Design.
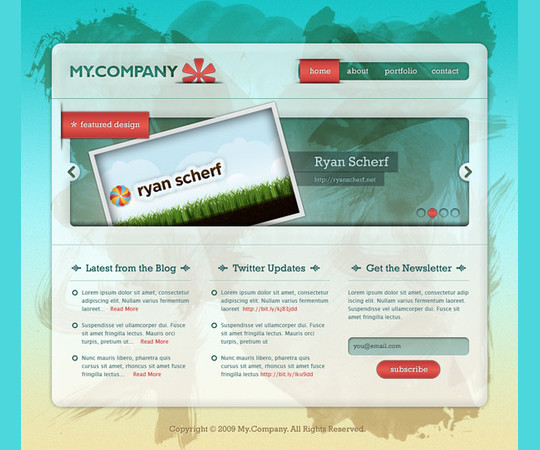
Design a Cool Textured Portfolio Website
In this tutorial you will learn how to Design a Cool Textured Portfolio Website.
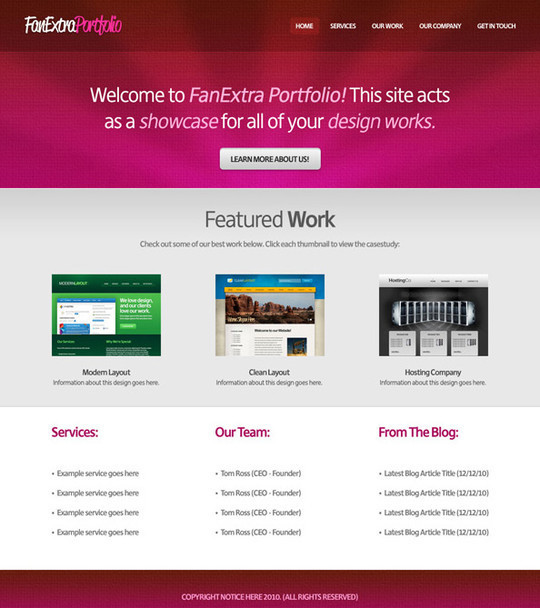
Create a Clean Business Web Layout in Photoshop
In this tutorial we would like to show you how to design a clean and solid fictional business layout. Following the steps in this tutorial you will learn how to use guides, how to create a detailed background using patterns and filters, how to create transparent buttons, 3D elements and how to stylize web typography. Hope you will find this tutorial useful and techniques shown in this tutorial will help you in future projects.
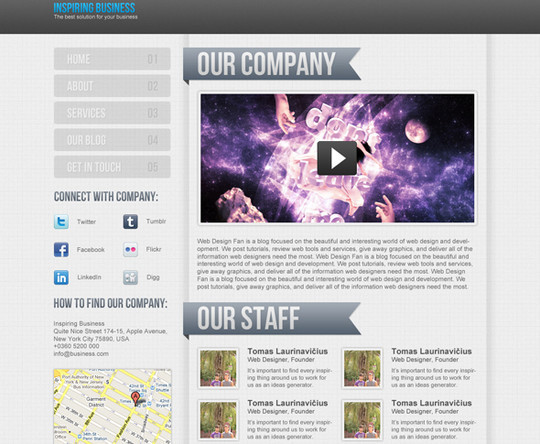
Design a Clean Business Layout
Grunge layouts may be all the rage right now, but they aren’t suitable for every kind of website. For this tutorial we are going to show you how to make a professional, clean business layout. This kind of design is perfect for companies or business related blogs.
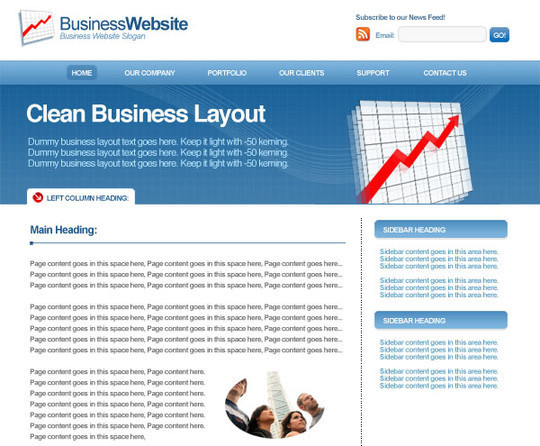
Portfolio Gallery Layout
In this tutorial you will learn how to create a portfolio styled layout for your design studio gallery. If you have any questions about this tutorial be sure to ask in the comments. Also, remember with all the tutorials, the psd is available for download.
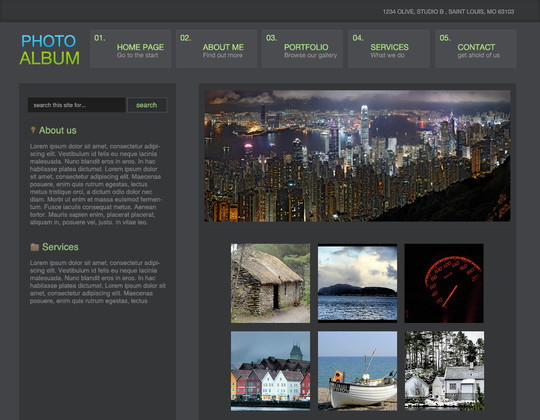
Creative Studio Web Page
In this detailed tutorial we will learn how to create impressive layout for Creative Studio.

Portfolio Layout
Welcome to another portfolio layout tutorial, in this tutrial il show you how to create a cool blue portfolio layout.

Create a Slick and Minimalist Web Layout in Photoshop
In this Photoshop web design tutorial, we’re going to learn how to create a slick and minimal-looking website layout. We will use the 960 Grid System as a template to make it easy to align the design elements on the layout.
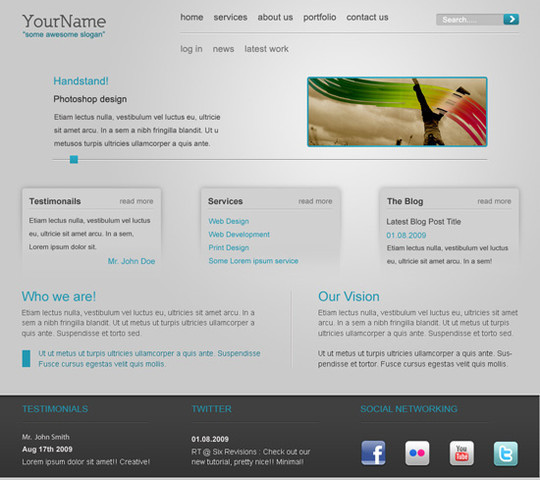
Design a Dark Business Layout
In this tutorial we will use only a few colors to create a dark business layout. With small modifications this layout can be used also as an wordpress blog. It is very important to use patterns in your layouts. We have a set with 200 seamless pixel patterns, and this little piece of graphics can change the look of the website very much.

How to create a web hosting layout
Today will show you how to create another eye catching hosting layout. In this tutorial we will use only 2-3 colors, with small variations, and you can use this layout for any internet business you have. of course you need to make small changes.

Design a Bold and Vibrant Portfolio
In this tutorial we will learn how to design a Bold and Vibrant Portfolio.
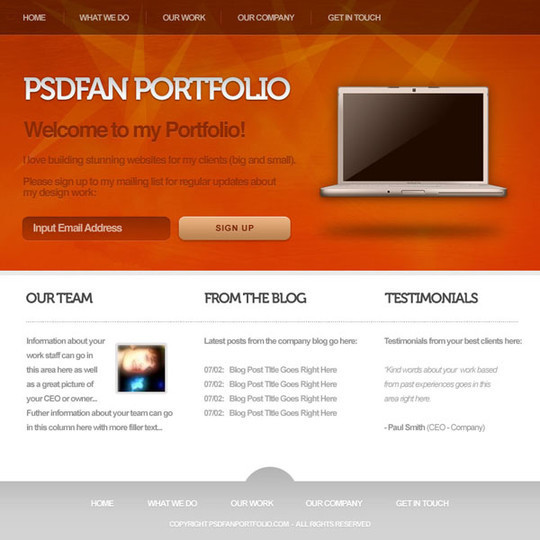
Design a Modern, Textured Portfolio Website
In this tutorial we will learn how to design a Modern, Textured Portfolio Website.
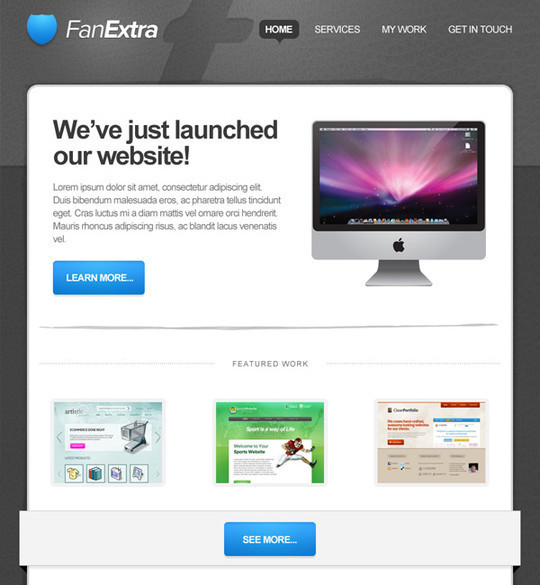
Design a Space Themed Portfolio Landing Page
In this tutorial we will learn how to Design a Space Themed Portfolio Landing Page.
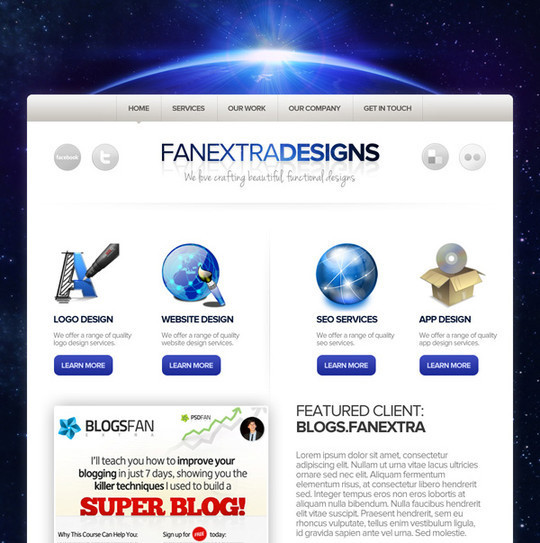
Design a Creative Unusual Layout
In this tutorial we will show you how to manipulate some simple shapes, to obtain a wonderful layout. As you have seen I am trying to create unusual layouts. I want to show you that it is possible to create also another type of layouts (not usual ones).

Create a Stylish Business Layout in Photoshop
In this tutorial we will show you how easy we will create a clean corporate layout. We wanted to create a website for a freelancer but after the first steps I’ve changed my mind.

Create a Clean Elegant WordPress Theme
In this tutorial we will show you how easy we will create a clean corporate layout.
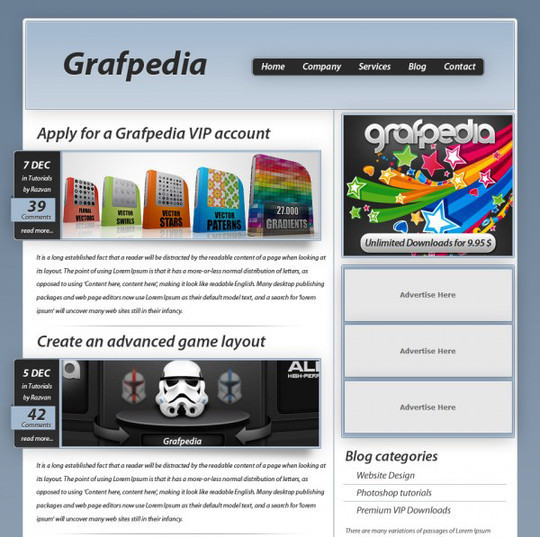
Design a Car Dealer Website Layout with Photoshop
Here we will show you how to create a car layout. This template can suite as a design for car dealers, communities dedicated to cars and other related topics. With some small modifications you can use this layout for a WordPress blog too.
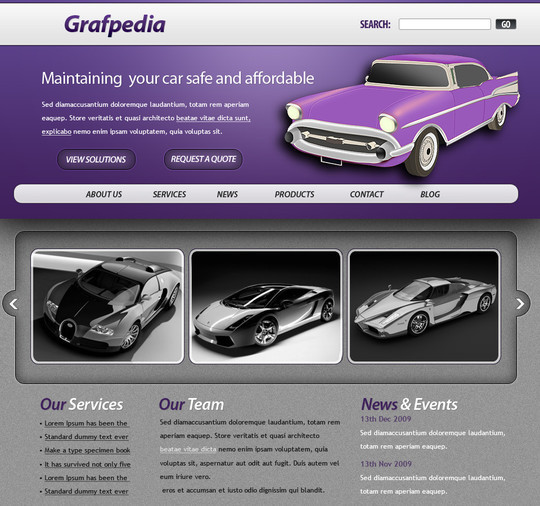
How to design a clean and beautiful portfolio webdesign
This Photoshop tutorial teaches you how to create a website layout, from the beginning, creating a document under Photoshop, how to the publication in HTML5 and CSS3. This tutorial is really useful for people willing to create their own website as well as for web designers looking for inspiration or looking for graphics resources.
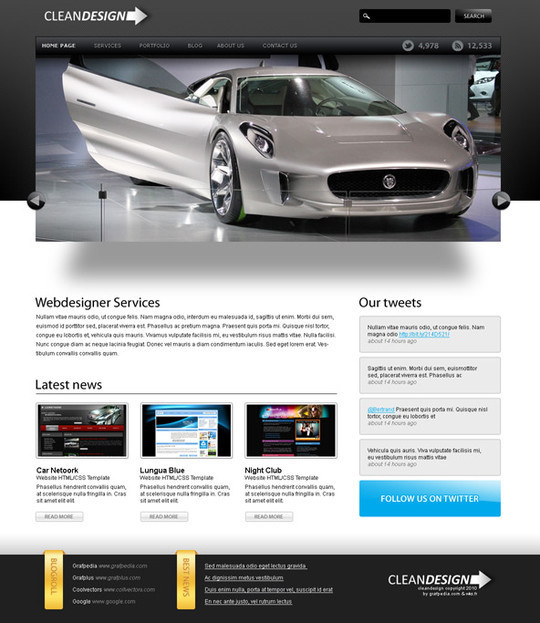
Create a Grunge Personal Portfolio Layout
In this tutorial we will show you how to create a grunge personal portfolio. With small modifications you can use this layout for a photography website or for a web design agency layout.

Create a Grunge Photographer Layout
In this tutorial we will show you how to create a grunge layout for a photographer. We will use some of the vectors we have already released in the past days, and we will show you how to manipulate them to create a nice looking layout. This layout can be used also for a portfolio layout.

Create a Chalkboard Style WordPress Layout in Photoshop
In this tutorial you will learn how to create a unique and original WordPress style layout that looks like a chalkboard. If you have any questions about this tutorial be sure to ask in the comments. Also, remember with all the tutorials, the psd is available for download.

Create a Racing Website
We are going to create a racing website using Photoshop and a little imagination, along with a few stock images. In this tutorial we are going to learn to create an easy glossy type, quick color correction, several visual elements and the structure of a website.

Create a simle layout for Architecture or Real Estate
In this tutorial we will show you how to create a simple layout for architecture business. This layout can be used if you want a website for an architectural or building company or for real estate development, structural engineering, and architectural consulting.
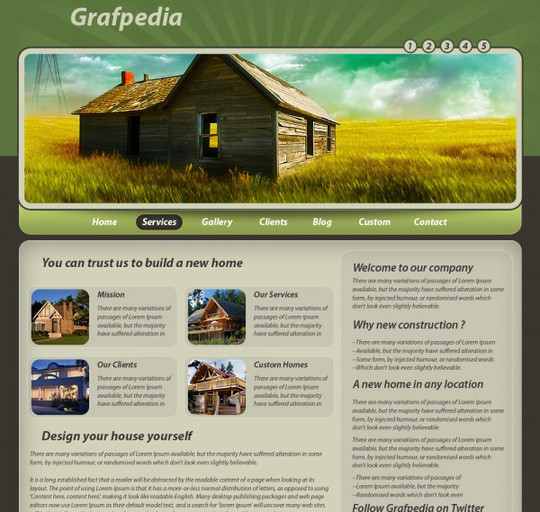
Design an Elegant Rustic Layout
Here we will create a layout for a hotel. This layout will work also if you have site related to the hotel industry: bed and breakfast, motels, and it will work very good for restaurants, cafes, pizzerias , bars, wineries layouts, etc.

How to Create the Interior Design Layout
In this tutorial you’ll learn how to create professional and glossy website layout for the Interior Design related company. Just follow the steps of this tutorial and you’ll find out that there is nothing so complicated in designing this stunning template.

Design a Creative Design Studio Layout
This PSD layout is aimed at design studios and agencies, designers, those involved in site design and software development, as well as graphic designers. With this design studio layout you can showcase your work or products in an easy way.

Design a Creative Cosmetics Layout with Photoshop
In this tutorial we will show you how to create a beauty layout based on some strange shapes. This PSD layout is aimed for building websites related to healthcare, medicine and health issues. It can be used for massage spa salons, spa resorts, body spa and facial spa accessories, spa equipment too.

Learn How To Create A Clean Layout In Photoshop
In this Photoshop tutorial we’ll learn how to create a clean looking website layout, we’ll also be using 960s grid system to keep everything aligned. This is very detailed tutorial, so if you have basic knowledge about Photoshop you should be able to easily keep up and let me guide you through this layout creation process.

How to create a distinguishable textured web layout in Photoshop
In this tutorial we will show you how to create a textured web layout, starting from the concept on paper to Photoshop design. We will discuss about site structure and will use the 960 grid to organize our contents. Also you will learn how to use layer styles to create an engraved text effect. Give it a try!
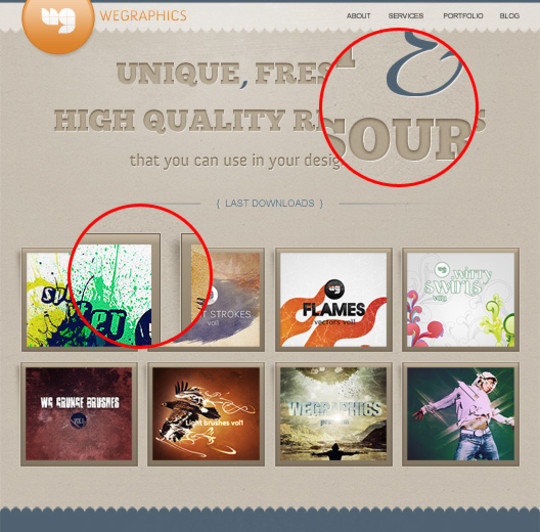
Clean and Minimalistic Portfolio Layout in Photoshop
In this tutorial you will learn how to create a clean and minimalistic portfolio layout in Photoshop. If you have any questions about this tutorial be sure to ask in the comments. Also, remember with all the tutorials, the psd is available for download.
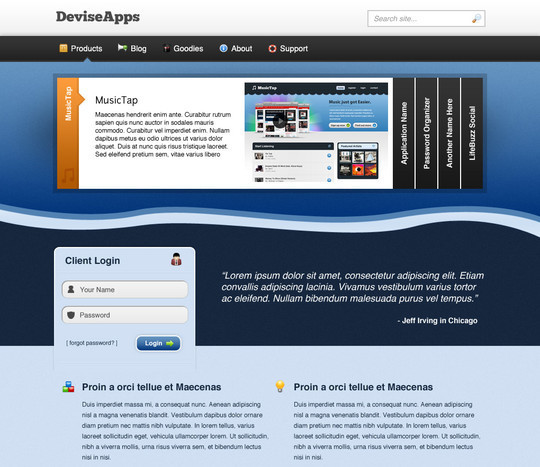
Create a Vibrant Professional Web Design in Photoshop
Developing a workflow that lets you create web layouts quickly and easily while still satisfying your clients’ needs is crucial. In this Photoshop web design tutorial, I’ll show you a way to create a slick home page layout in the fastest time possible and with minimum web design skills. Let’s go!
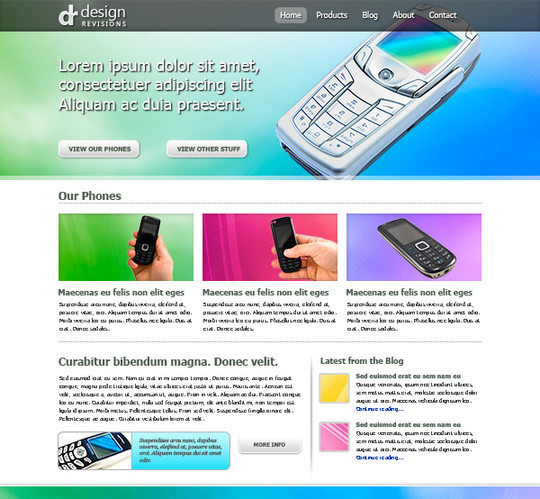
How to Create a Unique WordPress Theme
Here we try to create another creative layout which can be converted very easy in a wordpress theme.

Related posts:
- Best Of 2011: 45 Photoshop Web Design Layout Tutorials
- 50 Truly Eye-Catching And Detailed Web Layout Tutorials
- Fresh And High Quality Adobe Photoshop Tutorials
- Best Of 2011: Ultimate Collection Of High Quality Photoshop Tutorials
Read more: http://www.smashingapps.com/2012/12/10/40-high-quality-photoshop-web-layout-tutorials.html#ixzz2EnViWBf1
