
반응형
seaborn: statistical data visualization
seaborn.pydata.org/examples/index.html
Example gallery — seaborn 0.11.0 documentation
seaborn.pydata.org
반응형
seaborn.pydata.org/examples/index.html
Example gallery — seaborn 0.11.0 documentation
seaborn.pydata.org
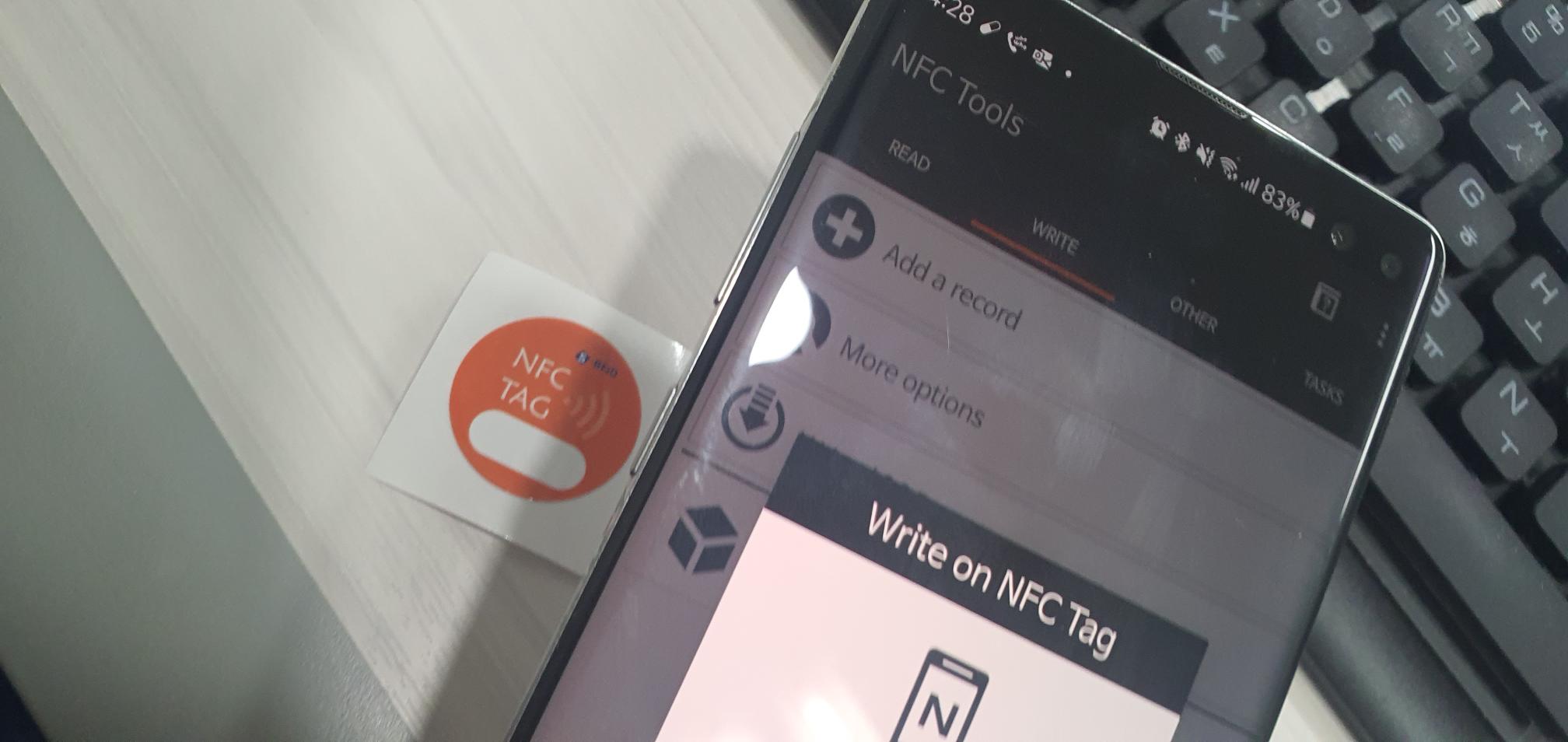
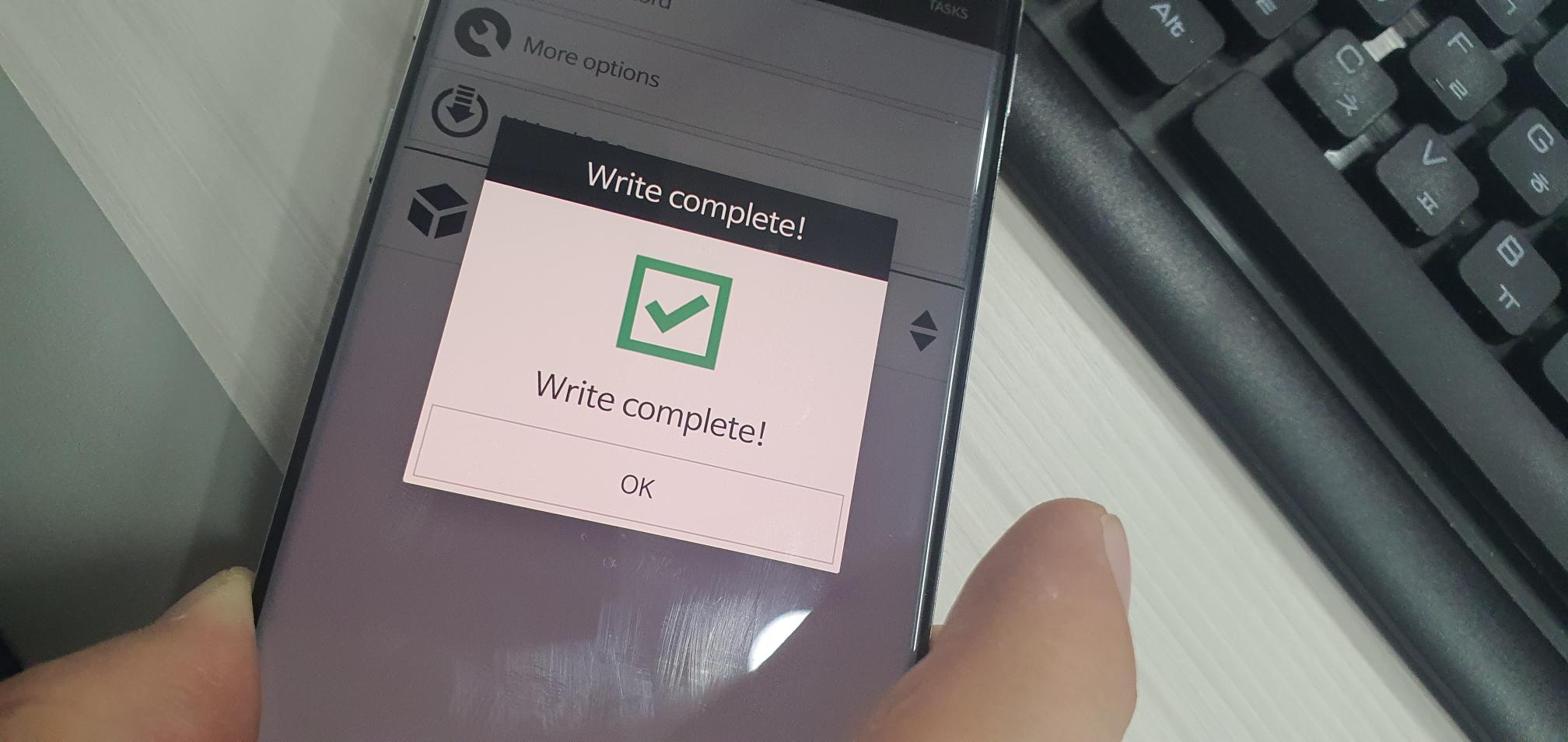
NFC 태그를 구매해서 NFC Tool을 이용한 태그 등록
play.google.com/store/apps/details?id=com.wakdev.wdnfc&hl=ko
NFC Tools - Google Play 앱
NFC Tools is an app which allows you to read, write and program tasks on your NFC tags and other RFID compatible chips. All you need to do is get your device close to an NFC chip to read the data on it or execute tasks. Simple and intuitive, NFC Tools can
play.google.com


| 안드로이드 ADID 확인 (0) | 2021.03.11 |
|---|---|
| MS Azure 사용안하는데 과금이 돼서 취소/환불 받기 (0) | 2020.12.22 |
| [JAVA] jdk8 다운로드, Konlpy jvm 에러 해결. No JVM shared library file (jvm.dll) found. Try setting up the JAVA_HOME environment variable properly (0) | 2020.12.02 |
| [콘솔] ConEmu - Windows Terminal : DOS 창, CMD창 (0) | 2020.11.26 |
| 카톡 오픈채팅 ‘방장봇’ 생긴다 (0) | 2020.11.13 |
리텐션을 높이는 힙한 서비스의 비밀
자이가르닉 효과
자이가르닉 효과(Zeigarnik Effect)란 마치지 못하거나 완성하지 못한 일을 쉽게 마음 속에서 지우지 못하는 현상으로 '미완성효과'라고도 한다.
‘끝마치지 못하거나 완성되지 못한 일은 마음속에 계속 떠오른다.’는 것으로, 러시아의 심리학과 학생이던 블루마 자이가르닉과 그녀의 스승이자 사상가인 쿠르트 레빈이 제시한 이론이다.
자이가르닉은 식당 종업원이 많은 주문을 동시에 받아도 그 내용을 모두 기억했지만 주문된 음식에 대한 계산된 후에는 무엇을 주문했는지 기억하지 못하는 것에 착안해 이 연구를 시작했다. 한 그룹은 일을 끝내도록 설정하고 다른 그룹은 일을 끝마치지 못하게 방해를 하는 실험을 한 결과 업무 종료 후 일 도중에 방해를 받은 그룹이 자신이 수행한 업무에 대해 더 잘 기억했다는 결과를 얻었다. 이루어지지 못한 첫사랑을 안타깝게 기억하는 것 또한 자이가르닉 효과에 해당한다.
즉, 어떤 일에 집중할 때 끝마치지 못하고 중간에 그만두게 되면 이 문제가 해결되지 않는 한 긴장상태가 계속되고, 긴장이 지속되다 보면 머릿속에 오랫동안 남아 있게 된다는 이론이다. 예컨대 끝내 이루어지지 않은 첫사랑을 더 오래 기억하는 심리현상이 이 효과의 대표적 사례라 할 수 있다.
자이가르닉 효과는 경제용어로도 많이 사용되고 있으며 다양한 티저 광고나 마케팅, 게임, 방송 등에 활용하기도 한다. 드라마는 중요한 장면에서 끝내는 경향이 있는데 이 또한 시청자들이 완성되지 않은 내용을 완결시켜야 한다는 관념에 사로잡혀 시청률을 유지하는 데 도움이 되기 때문이다.
그렇다면 이러한 자이가르닉 효과를 벗어나기 위해선 어떤 일을 시작했으면 가급적 결말을 짓는 게 좋다. 그렇지 않으면 계속 그 일이 머리에 남아 다른 일에 몰입하는 것을 방해한다. 그런데 만약 도중에 그만둘 수밖에 없는 상황이라면? 그럴 때는 "이것으로 이 일은 끝이야!"라고 선언하고 적절한 종결 의식을 행하는 등의 방법으로 그 일로부터 벗어나는 것이다.
www.youtube.com/watch?v=UV0nnzjmj8k
리텐션을 높이는 힙한 서비스의 비밀
용량이 없어도 삭제되지 않는 앱 만들기 | 2020.11.28 written by 황지혜 ✉️ jihye6523@gmail.com ✏️ Facebook / LinkedIn 힙서비콘 1기 (힙한 서비스들의 비밀 UX 컨퍼런스) 에서 연사로 발표했던 '리텐션을
brunch.co.kr
www.notion.so/c3cd36fb87c44e6199683f81934837c3
리텐션을 높이고, 앱삭제율을 줄이는 힙한 서비스의 비밀
2020.11.28
www.notion.so
| ‘넷플릭스법’ 닷새 만에 구글 ‘먹통’…정부 “자료 제출해라” (0) | 2020.12.15 |
|---|---|
| Saas 서비스 (0) | 2020.12.10 |
| [순서도] draw.io 웹에서 순서도 그리기, 구글드라이브 연동 (0) | 2020.11.30 |
| 행(hang)과 데드락(deadlock)의 차이 (0) | 2020.11.23 |
| 2020년 기업의 디지털트랜스포메이션 전략은 어떻게 변화되고 있는가? (0) | 2020.11.17 |
| [ASP] 페이지 로딩완료 전 로딩 이미지 보여주기 (0) | 2021.03.19 |
|---|---|
| REST API 제대로 알고 사용하기 (0) | 2021.03.17 |
| 왓챠, 이스터에그 중 루모스, 볼드모트 해봄. (0) | 2020.12.03 |
| [ASP] random 적용 난수 발생 (0) | 2020.11.24 |
| AWSOME DAY 온라인 컨퍼런스 (0) | 2020.11.24 |
왓챠, 이스터에그 중 루모스, 볼드모트 해봄.

| REST API 제대로 알고 사용하기 (0) | 2021.03.17 |
|---|---|
| 전화대신 채팅상담 - channel.io (0) | 2020.12.04 |
| [ASP] random 적용 난수 발생 (0) | 2020.11.24 |
| AWSOME DAY 온라인 컨퍼런스 (0) | 2020.11.24 |
| Active Server Pages (ASP) (0) | 2020.11.17 |
[chrome] 크롬 화면 분할 확장프로그램
우선 설정 > 모양 > 테마 (Chrome 웹 스토어 열기) 클릭
웹 스토어에서 확장 프로그램을 검색한다. Split Tabs 라는 프로그램이다.

Split Screen made easy. Resize the CURRENT tab and tabs to the RIGHT into layouts on separate windows. w/ Multi Monitor Support.
For a more easily readable description please visit:
https://github.com/peterdotjs/tab-resize
***** Version 2.3.0
--------------------------
Added default shortcut keys for:
Ctrl + Shift + Z: Undo Last Resize
Ctrl + Shift + 1: 1x1 Resize
Ctrl + Shift + 2: 1x2 Resize
Ctrl + Shift + 4: 2x2 Resize
www.youtube.com/watch?v=GFHl98nAV04
브라우저 상단에서 설정할 수 있다.

| [API] API 신청 - 보건복지부_코로나19 감염_현황 (0) | 2020.12.16 |
|---|---|
| 코로나 시대 이후 점차 적응되어 가는 화상회의 , 언택트, 온택트 (0) | 2020.12.15 |
| "자바 두명 타세요" 개발자 인력시장에 비유한 SW채용박람회 (0) | 2020.12.03 |
| feature complete (0) | 2020.11.26 |
| 정량평가 vs 정성평가 (0) | 2020.11.25 |
